If you’re new to scroll-driven animations, welcome! To start, it might be a good idea to read this beginner-friendly introduction before diving into this guide. I touch on animation-ranges briefly in that article and here I’ll go deeper, covering the different values and what they mean. Let’s begin!
First, let’s do a quick recap of what animation-range is.
animation-range is used along with the view() timeline. That’s the timeline you would select if you wanted the animation to happen when the user is scrolling and your element is visible in the viewport.
But saying that my element is “visible in the viewport” can mean a lot of things. Here are the different ways in can be interpreted.
Let’s say that the element you want to animate is a photo with a height of 300px.
Does “visible in the viewport” mean you want to start the animation as soon as the first pixel comes into view? Or do you want to wait until the whole photo is visible? What if you want to start the animation when the photo is halfway through the page? Or if you want to stop the animation when it’s almost off the page, but not quite? So many options!
animation-range gives you the ability to be that specific, allowing you to be very particular in when exactly you start and stop your animation.
Definitions
animation-range is actually a shorthand for two properties: animation-range-start and animation-range-end.
animation-range-start allows us to specify when the animation will start and animation-range-end declares when the animation will end. For this article, we’re going to focus on the shorthand.
The shorthand can accept two kinds of values. The first is a timeline-range-name and the second is the length-percentage. Let’s dig into the timeline-range-name first.
The timeline-range-name defines the start and stop of the animation based on where the element is in relation to the viewport.
Let’s look at an example to illustrate.
Say you have an image that’s 300x200px in a container that’s 1000px wide. You want to start that image all the way to the right and have it slide over to the left of the container as you scroll.
Now you have to decide — at what exact point do you want to start your sliding animation?
Cover
If you want to start your animation as the first pixel of your image enters your viewport, then you want to use the range cover. If used alone, it will set the start of the timeline (the 0%) right as the image peeps its head into view.
And it will slide your photo over to the left, all the way until the end of the timeline (the 100%) which is defined by the moment when the very last pixel disappears from view.
This means that even when just a sliver of the photo is in view, it will be animated. And when half of the photo disappears, it will still be animated, all the way until the image is completely gone.
Contain
If you want the animation to begin once the image is in full view and end right before it starts to exit, you’ll need a new range: contain.
Here, the animation doesn’t begin on the first pixel — it waits until it’s fully visible. And when your image has reached the top and the first pixel disappears, the animation stops.
Entry
What if you want the entire animation, the start of it and the end of it, to all happen only as your photo enters the viewport? That means that when the first pixel appears on the screen, the animation begins. And when the the last pixel finishes entering the viewport, that animation stops. That’s what entry is for.
There’s another entry-related range called entry-crossing. It’s similar to how entry works with a key difference. entry starts the animation when the first pixel of the image enters the viewport, which marks the 0% point in your timeline. It ends the animation, marking the 100% point in your timeline, when the last pixel has fully entered the viewport.
But what happens when the height of the image is bigger than the height of the viewport? Is the end of our timeline, the 100% point, set as the moment the image first takes up the available viewport even if part of the image is still hidden and hasn’t yet entered the viewport? Or do you wait until the last pixel has crossed the entry and all of the image has passed through the viewport?
You can specify both scenarios with entry and entry-crossing.
If you pick entry and your image height is taller than your viewport, you reach the end of your timeline, the 100%, and end the animation as soon as your image fills the viewport.
Here’s what that looks like:
But if you pick entry-crossing , the 100% is set to when the last pixel in the image has crossed the entry and entered the view port, like this:
exit follows the same idea as entry, but instead of setting the 0% and 100% when the image enters the viewport, it sets it when the image exits the viewport.
It looks like this:
Exit-crossing (vs. exit)
exit-crossing has the same idea as entry-crossing . The difference between exit-crossing and exit is easiest to appreciate when the height of your image is taller than the viewport, so let’s look at an example with a tall image to illustrate.
When you use exit for an image that’s taller than its viewport, the 0% is set when the last pixel has entered the viewport and the 100% is set when the last pixel has disappeared, leaving the viewport.
But for exit-crossing , the 0% is set at the point where the first pixel begins to exit the viewport, crossing the viewport’s edge, and the 100% is set when the final pixel disappears, like this:
That covers the different timeline-range-name s. They give you really great control of exactly when you want your animation to start and stop.
And for even more options, you can mix and match them. If you want to start your animation when the image first comes into full view but you want the animation to continue until the last pixel leaves, you can do this:
You might recall from earlier in this post that animation-range is a shorthand, so here I’ve provided the first value which is for my animation-range-start and the second is for my animation-range-end . And that’ll get me what I’m looking for.
Length-percentage
But let’s say you want to switch things up a bit. You don’t want to start your timeline until the image is fully visible, so you’re going to keep your first value as contain , but you want the animation to start halfway through your timeline, at 50%.
That means you need to explicitly set your <length-precentage> value in your animation-range , like this:
The <length-precentage> value type that can take a percentage or a length of any unit, giving you even more options and flexibility.
The options
So, if we wanted to customize every aspect of our animation-range value, we could define a animation-range-start and animation-range-end, declaring a timeline-range-name and length-percentage value for each.
And as a recap, the values for timeline-range-name are:
cover
contain
entry
entry-crossing
exit
exit-crossing
If we don’t declare any <length-percentage> values, they default to a start of 0% and an end of 100%. And if we don’t declare a timeline-range-name, it’ll default to a start of entry and an end of exit.
What will you animate with scroll-driven animations?
Let us know. Send me, Saron Yitbarek, a message on BlueSky, or reach out to our other evangelists — Jen Simmons, on Bluesky / Mastodon, and Jon Davis, on Bluesky / Mastodon. You can also follow WebKit on LinkedIn. If you find a bug or problem, please file a WebKit bug report.
Safari Technology Preview Release 223 is now available for download for macOS Tahoe and macOS Sequoia. If you already have Safari Technology Preview installed, you can update it in System Settings under General → Software Update.
Added support for allowing declarations directly inside @scope rule without a style rule ancestor. (296262@main) (145101643)
Resolved Issues
Fixed: Apply space from align-content when grid container and rows have definite sizes during column sizing (296300@main) (85252183)
Fixed <frame> and <frameset> to always be in-flow and non-floating. (296236@main) (102670652)
Fixed style container query on :host CSS pseudo-class to be correctly applied to slotted elements. (296080@main) (147684247)
Fixed space-around and space-evenly to fallback to safe center for align-content. (296239@main) (153403381)
Fixed the serialization of <color> custom properties to provide the used value. (296337@main) (153675017)
Fixed clamping the result of progress() between 0 and 1. (296440@main) (153895964)
JavaScript
New Features
Added support for Intl.Locale.prototype.variants getter. (296467@main) (153939662)
Resolved Issues
Fixed RegExp#[Symbol.search] to throw TypeError when lastIndex isn’t writable. (296443@main) (146488846)
Fixed DateTime string parsing for ISO8601 inputs. (296339@main) (153679940)
Fixed toIntegerOrInfinity to truncate negative fractional values to +0.0. (296468@main) (153939418)
Rendering
Resolved Issues
Fixed a list-style-position: inside list item marker to be rendered as the first child of the list item. (296451@main) (79587134)
Fixed using setDragImage with a fixed-position element, so that the drag preview bitmap includes the correct content. (296117@main) (90120656)
Fixed integrating popovers with anchor positioning. (295995@main) (141094328)
Fixed box-shadow with spread on a border-radius box to scale the radii correctly. (296481@main) (149490613)
Fixed SVG transform translate(X) not equal to translate(X,0). (296008@main) (151643419)
Fixed border-image repaint code is broken in some writing modes. (296016@main) (152396671)
Fixed box-shadow to repaint correctly in vertical-rl and horizontal-bt writing modes. (295977@main) (152803240)
Fixed border to no longer be adjusted in computed style for elements with native appearance (296129@main) (153152167)
Fixed margin-trim to not trim inline margins on block-level boxes, regardless of their position. (296212@main) (153240895)
Fixed text-wrap-style to not constrain single line content. (296471@main) (153755326)
SVG
Resolved Issues
Fixed handling of auto for rx and ry on <ellipse>. (296195@main) (153274593)
Text
Resolved Issues
Fixed Korean counter styles to be aligned with manual Korean numbering in lists. (296203@main) (152969810)
Web API
Resolved Issues
Fixed the mousemove event to be fired when the mouse stays in the document but there is no element. (296341@main) (120551245)
Fixed IntersectionObvserver to notify observers asynchronously. (296279@main) (152684301)
Web Extensions
New Features
Added support for dom.openOrClosedShadowRoot() and element.openOrClosedShadowRoot. (296168@main) (153118095)
Resolved Issues
Fixed high priority redirects to supercede low priority blocks for declarativeNetRequest. (296000@main) (145241581)
Fixed CSS display: none matching everything still getting applied even after an ignore-following-rules action was matched. (296149@main) (152996225)
Fixed calling scripting.registerContentScripts() sometimes returning the error: “Error: Invalid call to scripting.registerContentScripts(). Failed to add content script.” (296093@main) (153001967)
Web Inspector
Resolved Issues
Fixed clicking on the “+” button in the Sources tab sidebar doing nothing when Web Inspector is undocked. (296458@main) (153193833)
Update on what happened in WebKit in the week from June 30 to July 7.
Improvements to Sysprof and related dependencies, WebKit's usage of
std::variant replaced by mpark::variant, major WebXR overhauling,
and support for the logd service on Android, are all part of this
week's bundle of updates.
Cross-Port 🐱
The WebXR support in the GTK and WPE WebKit ports has been ripped off in preparation for an overhaul that will make it better fit WebKit's multi-process architecture.
Note these are the first steps on this effort, and there is still plenty to do before WebXR experiences work again.
Changed usage of std::variant in favor of an alternative implementation based on mpark::variant, which reduces the size of the built WebKit library—currently saves slightly over a megabyte for release builds.
Adaptation of WPE WebKit targeting the Android operating system.
Logging support is being improved to submit entries to the logd service on Android, and also to configure logging using a system property. This makes debugging and troubleshooting issues on Android more manageable, and is particularly welcome to develop WebKit itself.
While working on this feature, the definition of logging channels was simplified, too.
Community & Events 🤝
WebKit on Linux integrates with Sysprof and reports a plethora of marks. As we report more information to Sysprof, we eventually pushed Sysprof internals to its limit! To help with that, we're adding a new feature to Sysprof: hiding marks from view.
Safari Technology Preview Release 222 is now available for download for macOS Tahoe and macOS Sequoia. If you already have Safari Technology Preview installed, you can update it in System Settings under General → Software Update.
Fixed <figcaption> within a <figure> element to only contribute to the accessible name of an <img> element if the image lacks other labeling methods like alt, ARIA attributes, or the title attribute. (295746@main) (150597445)
Fixed handling of invalid values for aria-setsize and aria-posinset according to the most-recent revision of the ARIA specification. (295814@main) (151113693)
Fixed VoiceOver reading “Processing page %infinity” when loading large pages. (295858@main) (152617082)
CSS
New Features
Added support for implicit anchor elements for pseudo-elements with anchor functions. (295871@main) (152635393)
Media
Resolved Issues
Fixed video elements with WebM object URLs causing MediaError code 2. (295802@main) (151234095)
Rendering
Resolved Issues
Fixed CSS filters to establish a containing block like transform does. (295958@main) (119130847)
Fixed CSS gradient interpolation for “longer hue” gradients when an end color stop is omitted. (295860@main) (142738948)
Scrolling
Resolved Issues
Fixed inconsistent decimal values from getBoundingClientRect for sticky elements. (295783@main) (147163986)
Web API
Resolved Issues
Fixed the <option> element to not trim the label value and correctly handle an empty label. (295708@main) (151309514)
Update on what happened in WebKit in the week from June 24 to July 1.
This was a slow week, where the main highlight are new development
releases of WPE WebKit and WebKitGTK.
Cross-Port 🐱
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Made some further progress bringing the 32-bit version of OMG closer to the 64-bit one
Releases 📦️
WebKitGTK 2.49.3 and WPE WebKit 2.49.3 have been released. These are development snapshots intended to allow those interested to test the new features and improvement which will be part of the next stable release series. As usual, bug reports are welcome in the WebKit Bugzilla.
visionOS 26 brings a major update to an important building block for the spatial web: The HTML model element is enabled by default, with a new API that’s ready to use today.
The video above is an example of the model element in Vision Pro. You can visit the model element demos yourself on Vision Pro or in the visionOS Simulator.
Background
A new generation of computing devices offers the ability to create new, immersive experiences — and the web should be part of that. While WebXR and QuickLook are a great way to see spatial content, we believe there should be an easier way for existing websites to show traditional pages side-by-side with spatial content like 3D models. And while JavaScript libraries are doing a great job of creating an author-friendly API to integrate 3D content, we believe that open web standards that let browsers do the work of managing accessibility and privacy are a critical step toward a truly spatial web.
A simple API: Lights, Camera, Action
The model element is a proposal to do just that, by using a single HTML element that links to a 3D asset like a USDZ file. On a spatial platform like Apple Vision Pro, your users can see your model as a stereoscopically-rendered 3D object, just like it’s in a portal inside your web page. You can easily let users spin the model around with a single attribute. For more fine-grained control, authors can control a model’s scale, rotation, and position, manage its lighting environment, and control playback of an animation through a familiar playback API like <video> and <audio> elements. We’ve got more on USDZ files and how to make them at the end of the post.
The ready Promise
Any asset delivered over the web is going to take some time to get ready, and a 3D asset is no different. As a new feature on the modern web, model elements expose a ready Promise that you can await to ensure that all the work of downloading and processing the model contents has been completed and is available to work with in the browser:
Separate resources like lighting are signaled with another Promise – more on that later.
Orbit mode
One of the main things users do with 3D models online is explore them by rotating content to see from all sides. We wanted to make it easy to enable this interactivity, so it’s available by setting model’s stagemode to "orbit" . This is a signal that a pinch-and-drag in the horizontal axis will spin the model on its heading, and a vertical movement will pitch it up and down to see the top and bottom.
<modelstagemode="orbit"><sourcesrc="teapot.usdz"type="model/vnd.usdz+zip"><imgalt="a teapot for interacting with"src="fallback/teapot-orbit.jpg"></model>
This provides an interaction scheme that’s similar to AR Quick Look, and the default “orbit” behavior in many 3D apps on iOS on iOS, macOS and visionOS. But if you want to implement custom behavior to meet more specific needs, you can do it by modifying the entityTransform directly.
EntityTransform
In most 3D apps, the view is controlled with a camera, which specifies both the position that the image is viewed from, as well as details like the zoom level or Field of View (FoV). Because an in-line 3D model appears as a real 3D model, however, the “camera” is the user’s actual eyes – meaning that FoV and other traditional camera properties need to match the spatially-correct values for a model to appear correctly. To control the rest of these attributes, a model allows you to translate, rotate, and scale the scene around using the entityTransform attribute, which takes a DOMMatrix.
What is the DOMMatrix?
Even if you’ve never heard of DOMMatrix, you’ve probably used one before – it’s the object type created for CSS transforms, and already has an extensive API for creating them in Javascript too:
This sets the teapot back 0.5 meters in the Z-axis, and rotates it 90º on the Y-axis. You can build a matrix with the helper methods, but will need to be careful about the order of the transformations to make it work.
Initial size and bounding box information
A model file contains 3D data about one or more objects, which could be any size – from a microchip to a mountain bike. They can also be centered on any position: A character from a video game may be centered on the character’s feet, while a 3D object captured on your iPhone might be centered on the initial position of the phone at the time. To make it easier to work with, the initial entityTransform is aligned and scaled to fit the scene within the visible viewport. Once loaded, a model has boundingBoxCenter and boundingBoxExtents, specified as DOMPointReadOnly values. You can also use these to set the entityTransform yourself.
Next, for a model to look realistic, it needs to look like it’s lit by a realistic scene. The industry standard for doing that is by providing an environment map. This is an image of all the light that would illuminate an object, including not just direct “lights” like the sun but the light reflected back from the ground and other surfaces as well. Because the bright lights in an environment map are so much brighter than the rest of scene – often hundreds of thousands of times brighter – this “Image-Based Light” is best presented in a “High-dynamic Range” (HDR) format. Popular formats for representing HDR images are the OpenEXR format and the Radiance HDR format.
A neutral environment map is provided by default, and authors can specify a custom one by setting the environmentmap attribute on the element. Environment maps need to be supplied in the “equi-rectangular” projection, similar to the way a world map is drawn today:
Equirectangular projection of the earth, note the warping at the polesSpherical mapping of the equirectangular texture. Note the dots at and near the poles appear at the same scale as the dots at the equator.
You can make these resources yourself in tools like Blender. Websites like Polyhaven have a long list of Creative Commons environment maps in a range of sizes, and available in both HDR and EXR format. Because these files can also be large, it’s important to listen for their availability and load status – you can await the environmentMapReady Promise to guarantee that it’s downloaded and ready to contribute to rendering your content.
Finally, model files can have animated contents, using the familiar concept of an animation timeline. If there’s an animation in the source file, the model element will have a duration attribute, can be played and paused with play() and pause(). The animation can be seeked by setting the currentTime, and the animation’s speed can be changed by updating the playbackRate attribute. Finally, the default behavior of the element playback can be configured on declaratively with the autoplay and loop attributes in HTML.
Try it yourself: Using USDZ
If you’re creating experiences for AR Quick Look on iPhone and Vision Pro, you’ve got everything you need to get started. If you’re not familiar with USD, it’s short for “Universal Scene Description:” an industry-standard way of working with entire projects of 3D content, open sourced by Pixar in 2016 as OpenUSD. Today it’s supported by all major 3D software tools with help from the Alliance for OpenUSD. USDZ is a USD scene packed into a single file, ready to use in Quick Look for iOS, iPadOS and visionOS, and in model today in visionOS.
If you want to get started with the model element and don’t have any content yourself, you can find a great selection of USDZ model files in Reality Composer Pro, which comes with Xcode. If you have an iPhone or iPad with a LiDAR sensor, you can scan a 3D object with Object capture in Reality Composer, developed by Apple and free in the App store. Or if you want to get started with making your own models, the powerful and popular modeling tool Blender has excellent USD import and export built right in.
The features described in this post conform to the API proposal being considered by the W3C for the Model Element and the HTML specification managed by WHATWG. It’s a work in progress, so we’d love to hear your feedback and see what you make. To share your thoughts on the HTML model element, find us on Mastodon at @jensimmons@front-end.social, @jondavis@mastodon.social, or on X at @zachernuk. Or send a reply on X to @webkit. You can also follow WebKit on LinkedIn. If you run into any issues, we welcome your feedback about WebKit at bugs.webkit.org. Or, if the issue involves technology deeper in the stack, file feedback with a sysdiagnose to provide information on how the operating system itself is being impacted. Filing issues really does make a difference. Thanks.
Multiple MediaRecorder-related improvements landed in main recently (1, 2, 3, 4), and also in GStreamer.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
JSC saw some fixes in i31 reference types when using Wasm GC.
WPE WebKit 📟
WPE now has support for analog gamepad buttons when using libwpe. Since version 1.16.2 libwpe has the capability to handle analog gamepad button events, but the support on the WPE side was missing. It has now been added, and will be enabled when the appropriate versions of libwpe are used.
But linking these animations to user behavior like scrolling has traditionally required third-party libraries and a fair bit of JavaScript, which adds some complexity to your code. But now, we can make those animations scroll-driven with nothing more than a few lines of CSS.
Scroll-driven animations have increased browser support and are available in Safari 26 beta, making it easier for you to create eye-catching effects on your page. Let me show you how.
First, let’s break down the components of a scroll-driven animation.
A scroll-driven animation has three parts:
the target: the thing on the page that we’re animating
the keyframes: what happens to the element when the user scrolls
the timeline: what determines whether the animation proceeds
What’s great about these three parts is that two out of the three are probably already familiar to you.
The first, the target, can be whatever you want to move on your page, styled to your heart’s content.
The second, the keyframes, are the classic CSS animation that’s been around for years. Creating amazing scroll-driven animations largely depends on how great your animation is. If you’re new to CSS animations, check out MDN’s resource.
The third part, the timeline, might be less familiar, but it’s an important part of scroll-driven animation. Let’s explore it in more detail.
What are timelines?
Animations have a beginning, middle, and end, moving sequentially along a timeline. The default timeline on the web is called the document timeline and it’s time-based. That means that as time passes, the timeline progresses as well.
If I have an animation using the default timeline, it animates as time moves forward. If I start with a green circle and I want to animate a color change using the default timeline, then I might make it turn red in the first second, then blue a second later, then yellow on the third. The colors animate with time.
This is the way animations have worked for years. Then, the animation-timeline property was introduced as part of the CSS Animations Level 2 spec in June 2023. That allowed us to think of other things that might impact animation besides the passing of time, like a user scrolling up and down our webpage, and made scroll-driven animations possible.
With scroll-driven animations, we’re no longer using time. Instead, we have two new types of timelines to work with: scroll and view.
scroll() timeline
With scroll timelines, the animation doesn’t progress with time — it progresses based on the user’s scroll.
If the user starts scrolling, the movement begins. The moment the scroll stops, the movement stops too. It’s this new timeline that creates that link between scrolling and animation.
A common way to demonstrate how scroll-driven animations work is by creating a progress bar. In reality, since you already have scroll bars, you don’t need a progress bar like this, but it’s an easy-to-follow example, so let’s go with it.
The first thing to do is create my target, the element that we’re going to animate.
Let’s build that target as part of my website for a coding school, the A-School of Code. If we were to create a progress bar at the bottom of our page, we might add it as a pseudo-element of our footer. We want it to start at the bottom left and progress to the right.
That’ll get us a narrow yellow bar going across my page (highlighted by the pink arrow):
Next, we need our keyframes to create the actual animation.
We’re going to give our keyframe a custom name, let’s say “progress-expand,” like this:
@keyframes progress-expand {
from { width: 0% }
to { width: 100% }
}
Third, we need to use our new timeline — **** scroll(). This tells my browser that the animation should only take effect while my user is scrolling, making it a scroll-driven animation.
Note: Your animation-timeline property must be set after your animation property, otherwise, this will not work.
And just like that, you have your first scroll-driven animation.
Because we added motion to our page, there’s one thing we need to consider before we ship. Is the movement we just added going to cause any motion discomfort for our users? Is our page accessible?
The subtle, usually slow movement of a progress bar is unlikely to be a motion sensitivity trigger, partly because it’s not taking up much of the viewer’s field of vision. In comparison, larger, wider field-of-vision animations often simulate movement in three-dimensional space, using techniques like parallax, zoom, or depth-of-field like focal blur. Users with motion sensitivity are more likely to experience these larger animations as real movement in three-dimensional space, and are therefore more likely to experience other negative symptoms like discomfort or dizziness.
When in doubt, it’s a good idea to wrap your animation in a media query that checks for reduced motion preferences, like this:
@media not (prefers-reduced-motion) {
/* animation here */
}
That way, your animation will only run if the user has not set reduced motion preferences. To learn more about when to use prefers-reduce-motion, read our article, Responsive Design for Motion (https://webkit.org/blog/7551/responsive-design-for-motion/). In this case, I think our animation is safe.
Here are our final results:
Here’s all the code in one place for easy viewing:
The timeline we used in the example above, the scroll() timeline, becomes active as soon as we start scrolling, with no regard as to what’s visible to the user or when it shows up in the viewport.
That might be what you want, but more often than not, you want an animation to happen when your target element appears on the page.
Your element could be anything — a carousel, a menu, a gallery of images. But whatever it is, on most websites, the element you want to animate usually isn’t permanently visible on the page. Instead, it shows up as the user explores your site, poking its head into the viewport when you scroll far enough down the page.
So rather than activating the timeline when the user starts scrolling, you want the timeline to activate when the element appears in the viewport, and for that, we need a different timeline for our animation — the view() timeline.
To see how it works, let’s look at a simple example of an image sliding into place when it enters my viewport as we scroll.
I’ll start with a basic article using placeholder text and insert a few images at different parts of the page. Since the images are further down the article, they’re not in the viewport when the page first loads.
Let’s revisit the three things I need for my scroll-driven animation:
the target: the thing on the page that we’re animating
the keyframes: what happens to the element when the user scrolls
the timeline: what determines whether the animation proceeds
My targets are the images in the article, which I have in my HTML. Great! One down, two to go.
Next, I need to set my keyframes. That’s the animation part of scroll-driven animations.
I want two things to happen here — I want the image to fade in and I want it to slide in from the right. I can make that happen with the following code:
That gets us the nice sliding effect we’re looking for.
But there’s one more thing I want to do for this animation. You’ll notice that the picture doesn’t finish sliding into place until it’s almost out of the viewport. That means that our image is in motion the whole time it’s visible, and that’s not a great experience for our user.
What we really want is for it to slide into place and then stay there for awhile so the user can properly take it in without the distraction of all the movement. We can do that using another property called animation-range .
The animation-range tells our browser when to start and stop the animation along our timeline. The default range is 0% to 100%. The 0% represents the moment when the target element starts to enter our viewport. The 100% represents the moment when the target element completely exits our viewport.
Because we haven’t set our animation-range, we’re using the default values. That means that as soon as the first pixel of my image enters my viewport, my animation begins and it doesn’t end until the last pixel exits.
To make it easier for my users to actually see these images, I want the animation to stop when they’re about halfway through the viewport. At that point, I want the image to find its place and just stay there. To do that, I’m going to change my range to 0% and 50%, like this:
And this time, the animation stops when the image gets halfway up the page, just like I want.
Do you feel the difference of the change? Does it make it easier to view the images? Do you think a different range would be better? Asking ourselves these questions allow us to better understand what these changes mean for our users, so it’s good to take a moment to reflect.
Another thing to consider before we ship is the impact of this animation on our motion-sensitive users. Just like our previous example, since we’re introducing motion, we have to check if we’re triggering possible motion discomfort.
In this case, I have a bigger animation than my progress bar. The images on my page are pretty big, and if you’re not expecting them to move and you scroll too fast, they can zoom by. That can cause discomfort. Since I want to play it safe, I’m going to put this in a reduced motion query, so my final code will look like this:
There’s more you can do with the animation timeline and the animation range. Since scroll() and view() are functions, you can pass in certain values to truly customize how your scroll driven animation works. You can change the default scroller element. That’s the element with scroll bars where the timeline is set. If you pass nothing in, the default value for this is nearest and it’ll find the nearest ancestor with scroll bars. But you can also set it to root and self. The second value you can change is the scrollbar axis. The default there is block but you can also set it to inline, x, and y. Try the different values yourself and see how they work.
There’s more you can do around the entry and exit of your animated elements as well, to get the exact effect you’re looking for. We’ll cover those in a future post. In the meantime, play around with scroll and view timelines in Safari 26 beta and see how you can elevate the user interaction on your website or web app.
And when you do, tell us your thoughts on scroll-driven animations. Send me, Saron Yitbarek, a message on BlueSky, or reach out to our other evangelists — Jen Simmons, on Bluesky / Mastodon, and Jon Davis, on Bluesky / Mastodon. You can also follow WebKit on LinkedIn. If you find a bug or problem, please file a WebKit bug report.
Update on what happened in WebKit in the week from May 27 to June 16.
After a short hiatus coinciding with this year's edition of the Web Engines
Hackfest, this issue covers a mixed bag of new API features, releases,
multimedia, and graphics work.
Cross-Port 🐱
A new WebKitWebView::theme-color property has
beenadded to the public API, along with a
corresponding webkit_web_view_get_theme_color() getter. Its value follows
that of the theme-color metadata
attribute
declared by pages loaded in the web view. Although applications may use the
theme color in any way they see fit, the expectation is that it will be used to
adapt their user interface (as in this
example) to
complement the Web content being displayed.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
Damage propagation has been toggled for the GTK
port: for now only a single rectangle
is passed to the UI process, which then is used to let GTK know which part of a
WebKitWebView has received changes since the last repaint. This is a first
step to get damage tracking code widely tested, with further improvements to be
enabled later when considered appropriate.
Adaptation of WPE WebKit targeting the Android operating system.
WPE-Android 0.2.0
has been released. The main change in this version is the update to WPE WebKit
2.48.3, which is the first that can be built for Android out of the box,
without needing any additional patching. Thanks to this, we expect that the WPE
WebKit version used will receive more frequent updates going forward. The
prebuilt packages available at the Maven Central
repository
have been updated accordingly.
Releases 📦️
WebKitGTK
2.49.2 and
WPE WebKit 2.49.2 have
been released. These are development snapshots and are intended to let those
interested test out upcoming features and improvements, and as usual issue
reports are welcome in Bugzilla.
Safari Technology Preview Release 221 is now available for download for macOS Tahoe and macOS Sequoia. If you already have Safari Technology Preview installed, you can update it in System Settings under General → Software Update.
Fixed aria-expanded attribute support on navigation links. (295356@main) (141163086)
Forms
Resolved Issues
Fixed updating scrollbar appearance correctly for the page and <textarea> elements. (295590@main) (151496190)
Fixed programmatically assigned File objects to display the correct filename in <input> elements, even without a file path. (295458@main) (152048377)
JavaScript
Resolved Issues
Fixed nested negated classes resulting in incorrect matches. (295277@main) (151000852)
Media
Resolved Issues
Fixed MP4 seeking with b-frames to prevent out-of-order frame display by suppressing frames with earlier presentation timestamps following the seek point. (295304@main) (140415210)
PDF
Resolved Issues
Fixed “Open with Preview” button to open a PDF in the Preview app. (295475@main) (148680145)
Rendering
Resolved Issues
Fixed an issue causing a <canvas> element to disappear for one frame if a view transition occurs. (295467@main) (149709642)
Web API
Resolved Issues
Fixed escaping < and > when serializing HTML attribute values. (295149@main) (150520333)
Web Inspector
New Features
Added support for recording Workers in the Timelines tab. (295485@main) (151721737)
Resolved Issues
Fixed pretty-printing CSS to avoid adding a space after the universal selector (*) when followed by a pseudo-class or pseudo-element, preventing unintended changes to CSS selector behavior. (295447@main) (71544976) (FB8906066)
WebRTC
New Features
Added support for exposing a default system speaker device. (295206@main) (151761469)
Today brings the beta of Safari 26, with 67 new features and 107 improvements. We’ll take a tour of them all in this article. But first — Safari 26? Where is Safari 19?
You might have seen today during the WWDC25 Keynote that macOS, iOS, iPadOS, visionOS, and watchOS have all been relabeled to now share the same version number — 26 for 2026. Safari is being renumbered as well.
It was four years ago that we unified the Safari version numbers across platforms, and started marking every update with a X.Y number — including, for example: Safari 16.0, Safari 17.2, and Safari 18.4. This change made all of our releases much more visible to web developers. Both Can I Use and MDN BCD started showing data about the new web technology in all seven releases each year.
While the version number is jumping from 18.x to 26.x, the manner in which point releases of Safari contain significant improvements to the underlying web technology will stay the same. The changes that you care about most as someone who make websites will continue to appear all year around.
So, let’s take a look at the web technology arriving today in Safari 26 beta.
SVG Icons
Safari 26 beta now supports the SVG file format for icons everyplace there are icons in the interface, including favicons.
For years, favicons were just displayed in the browser window’s URL bar, or in a menu of favorites. Now, icons show up in a range of places across browsers, at wildly different sizes. That includes the Safari start page, where icons represent content in Reading List, iCloud Tabs, Suggestions and Favorites. For web apps, this same icon represents the website on the user’s Home Screen or in their Dock. And icons are, of course, used in Safari tabs and menus.
By using an SVG file for your icon, you leverage infinite vector scaling. You rely on Safari to do the work of creating rasterized icons at multiple sizes to be used in various locations. And an SVG file is also often a smaller download than the .png files commonly used for favicons.
Data URL images are also now supported for icons as well, allowing you to embed small files in documents.
Every site can be a web app on iOS and iPadOS
iPhone users have been able to put a website’s icon on their Home Screen for quick access since Jan 2008, with “Add to Home Screen” shipping in iPhone OS 1.1.3. Tapping the icon opened the site in Safari.
Eight months later, with iPhone OS 2.1, web developers could start configuring their website with “the standalone mode to look more like a native application” by using the <meta name="apple-mobile-web-app-capable" content="yes"> tag. In 2013, the W3C began the standardization process of Web Application Manifest, making it possible to configure web app behavior with a JSON manifest file. Support for Web Application Manifest started landing in browsers in November 2014, and was added to Safari with iOS 11.4 in March 2018.
For the last 17 years, if the website had the correct meta tag or Web Application Manifest display value, and the user added it to their Home Screen in iOS or iPadOS, tapping the icon opened it as a web app. If the website was not configured as such, tapping the icon opened the site in the browser.
On Mac, we took a different approach when introducing Web Apps on Mac in Sep 2023. There, it doesn’t matter whether or not the website has a Web Application Manifest — it always opens as a web app. We don’t want our users to experience a mysterious difference in behavior because of the presence or absence of invisible technology. Users should have a consistent experience.
Now, we are bringing this new behavior to iOS and iPadOS. By default, every website added to the Home Screen opens as a web app. If the user prefers to add a bookmark that opens in their default browser, they can turn off “Open as Web App”, even if the site is configured to be a web app. It’s up to users to decide. And the UI is always the same.
This change, of course, is not removing any of WebKit’s current support for web app features! If the site you built has a Web Application Manifest, then all of the benefits it provides will be part of the user’s experience. If you define your icons in the manifest, they’re used! If you want to provide an offline experience by using a Service Worker, great!
We value the principles of progressive enhancement and separation of concerns. All of the same web technology is available to you as a developer, to build the experience you would like to build. Just now, nothing is required beyond the basics of an HTML file and a URL to provide a web app experience to users. As a developer, you get to layer on whatever you want with CSS, JS, Web API, and more. And users get to add any site to their Home Screen, and open it as a web app.
HDR Images
The human eye can typically handle seeing things lit by bright light and sitting in dark shadows at the same time. The contrast your eyes see between brightness and darkness is called dynamic range, and it’s very challenging to reproduce.
As digital photography and videography improved by leaps and bounds over the years, the ability to digitally capture a dynamic range has greatly improved. The High Dynamic Range (HDR) format takes this even further, allowing you to capture both a wider dynamic range and increased color gamut, creating more vivid and realistic-looking images and video. Parallel breakthroughs in display technology have made it possible to present such images for others to view, with deep true blacks, pure bright whites and dramatic nuances in between.
WebKit shipped support for HDR video in Safari 14.0, in 2020. Now, in Safari beta for iOS 26, iPadOS 26, macOS 26 and visionOS 26, WebKit adds support for HDR images on the web. You can embed images with high dynamic range into a webpage, just like other images — including images in Canvas.
Safari 26 beta also adds support for the new dynamic-range-limit property in CSS. This property lets you control what happens when presenting a mix of standard dynamic range (SDR) and HDR video or images together. Currently, the Safari beta supports the no-limit and standard values. Using no-limit tells the browser to let content be as is — HDR content is presented in HDR. Using standard converts all of the HDR content to SDR, and displays it within the limits of standard dynamic range. Doing so prevents HDR images and video from appearing overly bright or out of place next to SDR content, which can be especially helpful when users or third-parties provide content.
WebKit in SwiftUI
WebKit has a brand-new API designed from the ground up to work with Swift and SwiftUI. This makes it easier than ever to integrate web content into apps built for Apple platforms.
The core parts of this new API are the new WebView and WebPage types.
WebView
To display your web content, simply use the new WebView type, a brand-new native SwiftUI View. All you need to do is give it a URL to display.
struct ContentView: View {
var body: some View {
WebView(
url:URL(string:"https://www.webkit.org")
)
}
}
WebView also supports a powerful set of new and existing view modifiers, like webViewScrollPosition, webViewMagnificationGestures, findNavigator, and more. For more advanced customization, like being able to react to changes in the content, you’ll need to connect it to a WebPage.
WebPage
WebPage is a brand new Observable class that can be used to load, control, and communicate with web content. You can even use it completely on its own, in cases where you don’t need to display the page directly to your users. But when you do, combining it with WebView allows you to build rich experiences, and integrate the web into your app with ease. WebPage has a full set of observable properties and functions you can use to make reacting to changes incredibly simple, especially with SwiftUI.
The new URLSchemeHandler protocol makes it super easy to implement handling custom schemes so that local resources and files can be used in your app. It leverages the full capabilities of Swift and Swift Concurrency, and you just need to provide it with an AsyncSequence.
WebPage.NavigationDeciding is a new protocol that lets you customize how navigation policies should behave in your app across different stages of a navigation. In addition to WebPage.NavigationDeciding, there’s also WebPage.DialogPresenting to customize how dialogs presented from JS should be displayed.
struct ArticleView: View {
@Environment(ArticleViewModel.self) privatevar model
var body: some View {
WebView(model.page)
.navigationTitle(model.page.title)
}
}
We look forward to seeing what Apple Developers do with the new WebPage and WebView types for Swift and SwiftUI. As a web developer, it’s now easier than ever for you to use the skills you have to create an app for iOS, iPadOS, macOS, and visionOS.
Now on visionOS, Safari supports the <model> element. It’s a brand new HTML element that’s similar to img or video — only now you can embed interactive 3D models into the webpage, and let users interact with them with a single attribute. And if they want to see your models in their own space at real size, they can drag the models off the page with a single gesture.
Basic usage
The syntax for showing a model is simple. Using the same USDZ files that work with AR Quick Look today, you can set the src attribute of the model element:
Lighting is an important part of making your 3D content look good, and the model element makes that straightforward too. You can apply an environment map as any image, including the high-dynamic range OpenEXR .exr and Radiance HDR .hdr formats by setting the environmentmap attribute:
<modelsrc="teapot.usdz"environmentmap="night.hdr"><imgsrc="fallback/teapot-night.jpg"alt="a teapot at night"></model>
Animation and playback
You can work with models containing animated content too. Use the autoplay attribute to declaratively set a model’s animation to run as soon as it loads, keep the animation going using the loop attribute,
<modelautoplayloopsrc="teapot-animated.usdz"><imgsrc="fallback/teapot-animated.jpg"alt="a teapot with a stowaway!"></model>
or use the JavaScript API for more fine-grained control:
constmodel=document.querySelector('model');
model.playbackRate=0.5; //set 50% speed
model.currentTime=6; //set the animation to 6 seconds in
model.play();
Rotation and interaction
To let users spin and tumble a model themselves, set the model’s stagemode attribute to orbit and everything will be handled for you.
<modelstagemode="orbit"src="teapot.usdz"><imgsrc="fallback/teapot-orbit.jpg"alt="a teapot for examining"></model>
Or if you’re after programmatic control, models can be scaled, rotated and moved (translated) using their entityTransform property, which can takes a DOMMatrix value. You can compose these with functions like translate, rotate and scale3d to orient the model the way you want.
<modelid="rotating-teapot"src="teapot.usdz"><imgsrc="fallback/teapot-rotater.jpg"alt="a teapot for turning"></model>
Safari in visionOS now supports a wider range of immersive media, including spatial videos and Apple Immersive Video, and 180°, 360°, and Wide FOV (field of view) videos that conform to the new Apple Projected Media Profile (APMP). Embed your video on a webpage, and let users play it back immersively on a curved surface in 3D space.
Safari also supports HTTP Live Streaming for all of these immersive media types. The existing HLS tools have been updated to support APMP segmentation, and the HLS specification has been updated with information on how to identify immersive media in an HLS manifest file.
WebKit for Safari 26 beta adds support for WebGPU.
WebGPU, a JavaScript API for running programs on the GPU, is similar to WebGL in its capabilities for graphics and rendering. Additionally, it adds compute shaders, which allow general purpose computations on the GPU, something not previously possible with WebGL.
WebGPU supersedes WebGL on macOS, iOS, iPadOS, and visionOS and is preferred for new sites and web apps. It maps better to Metal, and the underlying hardware. Comparatively, WebGL required significant translation overhead due to being derived from OpenGL which was designed prior to modern GPUs.
GPU programs are provided by the website or web app using the WebGPU Shading Language, known as WGSL (pronounced wig-sill). It’s a new language that is verifiably safe for the web unlike some existing shading languages which allow for unchecked bounds accesses and pointer arithmetic.
WebGPU has been enabled in Safari Technology Preview for over a year, and is now shipping in Safari 26 beta for macOS, iOS, iPadOS, and visionOS. Given the level of hardware access provided by WebGPU, much consideration was taken to ensure WebGPU does not expose new security attack surfaces. Additionally, validation performed was streamlined recently to minimize overhead and maintain closer to native application performance.
Anchor positioning is a new layout mechanism for anchoring one element to another on the web. It pairs well with the popover attribute (which shipped in Safari 17.0), making it easy to create responsive menus, tooltips and more. We are especially proud of the position-area syntax that makes using Anchor Positioning more intuitive. It’s an alternative to using syntax like this when the desired outcome is actually quite simple:
Above, we use the anchor() function in combination with top, left, bottom, right from absolute positioning. That combo can be powerful, and works well when your design calls for exact-to-the-pixel layout, anchoring to multiple anchors, or animated anchors. But often, you just want to tell the browser where to put an item, and have it figure out the details. Instead of the above, you can use code like:
The position-area syntax came from a proposal we put together, as we thought about how developers would use Anchor Positioning, and how overwhelming much of CSS layout can be.
Learn more about Anchor Positioning, and watch a full walkthrough of
this example in What’s new in Safari and WebKit at WWDC25.
You can also use position-try to make it responsive, giving it a new position to try (hence the name) if there’s not enough room to fully display the element.
Currently, this first beta of Safari 26 does not support position-visibility or the implicit anchor element. We’d love to hear from you as we continue to polish Anchor Positioning through this summer beta period, preparing for a fall release. You can file issues at bugs.webkit.org.
Scroll-driven Animations
Scroll-driven animations lets you tie CSS animations to either the timeline of just how far the user has scrolled, or to how far particular content has moved through the viewport, in and out of view.
For example, let’s imagine you want to animate a group of items as they scroll into view.
You can declare that you want the animation to be tied to whether or not they are in view with animation-timeline: view(), and specify that the animation should begin just as each item is 0% visible and end when they are 50% across the viewport with animation-range: 0% 50%.
Watch What’s new in Safari and WebKit at WWDC25 to see the full walkthrough of this example, and learn more about what’s possible with Scroll-driven animations.
Pretty text
Safari 26 beta adds support for text-wrap: pretty. Our implementation of pretty adjusts how text wraps in an effort to even out the ragged edge, improve hyphenation, and prevent short last lines.
In WebKit, all lines of text in an element are improved by pretty, not just a select group of lines at the end of the paragraph. To learn more, read Better typography with text-wrap pretty.
Contrast Color
Safari 26 beta adds support for the contrast-color() function. It lets you define a color by referencing another color and asking the browser to choose either black or white — whichever one provides more contrast.
For example, we can make a button with the background color of var(--button-color), and then ask the browser to set color to either black or white, whichever one provides more contrast against that background.
Safari beta adds support for the CSS progress() function. It’s a math function that returns a number value representing how far along something is, how much progress it’s made between two other values.
Let’s imagine at a particular moment, the is container 450px wide. That’s half way in-between 300px and 600px. The progress() function will calculate this to be 50% using this formula:
The result is always a number without any unit. Notice you can mix lengths with different units.
Be mindful that currently progressdoesn’t clamp. So it won’t stop at 0% or 100%. It will just grow above 100%, or shrink down below 0%.
The progress() function is most powerful when used with other complex math. Combine with animations, gradients, or scroll timelines, and connect one set of conditions with another. There might be even more functions with which it could be combined coming to CSS in the future.
And more CSS
Safari 26 beta now supports the margin-trim: block inline syntax for trimming in both directions. Learn all about margin-trim and what the block inline value does in Easier layout with margin-trim.
Safari 26 beta adds support for overflow-block and overflow-inline. These are the logical versions of overflow-x and overflow-y, making it easier to write robust code that supports multiple languages.
Now Safari supports the self-alignment properties align-self and justify-self in absolute positioning.
Digital Credentials API
WebKit for Safari adds support for the W3C’s Digital Credentials API. In jurisdictions that have issued such credentials, this API allows a website to securely request identity documents (e.g., a driver’s license) from Apple Wallet or other iOS applications that have registered themselves as an Identity Document Provider.
The Digital Credential API is useful for situations where a high-trust credential is needed to access a service online (e.g., renting an automobile). It provides a much safer and user friendly alternative to, for example, a user having to take a photograph of their driver’s license.
The Digital Credentials API leverages the existing Credential Management API and introduces a “digital” member for requesting identity documents. Requesting an identity document relies on the ISO/IEC 18013-7 Annex C international standard, which is identified by the protocol string "org-iso-mdoc".
For example, to request an end-user’s driver’s license, you might do something like this. Create a button in HTML:
asyncfunctionverifyIdentity() {
try {
// Server generated and cryptography signed request data.
constresponse=awaitfetch("drivers/license/data");
constdata=awaitresponse.json();
// Create the request.
constrequest= {
protocol:"org-iso-mdoc",
// What is being rquested, e.g. person's driving privileges
data,
};
// Perform presentment request.
// Must be done through a user gesture!
constcredential=awaitnavigator.credentials.get({
mediation:"required",
digital: {
requests: [request],
},
});
// Send credential to server for decryption.
constresponse=awaitfetch("/decrypt", {
method:"POST",
body:JSON.stringify(credential.data),
headers: {
'Content-Type':'application/json'
}
});
// Display it...
constjson=awaitresponse.json();
presentDetails(json);
} catch (err) {
// Deal with any errors...
}
}
To learn more about this transformative technology watch Verify identity documents on the web at WWDC25. And keep an eye on Issue 268516 for more about support of the Digital Credentials API in WKWebView.
Web API
Web developers can use the Trusted Types API, now supported in Safari beta, to ensure that end user input does not lead to client-side cross-site scripting (XSS). The API guarantees that input can be sanitized using a developer-specified function before being passed to vulnerable APIs.
We’ve added support for the URL Pattern Standard, which provides an efficient and performant way for web developers to match URLs using regular expressions through the URLPattern object. For instance, if your blog posts follow the pattern of /blog/title-of-the-post you could match them as follows:
Coming to Safari is the WebAuthn Signal API, which allows websites to report credential updates (like username changes or revocations) to credential providers, ensuring a more accurate and consistent user experience with passkeys. The new PublicKeyCredential.signal* methods enable websites to communicate these changes, improving credential management and streamlining sign-in flows. This enhancement empowers websites to provide a more seamless and secure WebAuthn experience.
There’s also now support for the File System WritableStream API, enabling direct writing to files within the user’s file system. This API provides an efficient and streamlined way to save data, allowing developers to build applications with enhanced file handling capabilities, such as direct downloads and in-place file editing.
WebKit for Safari 26 beta adds support for the alg parameter when importing or exporting Edward’s-curve based JSON Web Keys in WebCrypto.
Support for scrollMargin in IntersectionObserver is here for more precise intersection detection. This allows you to define margins around the root element, similar to rootMargin, providing finer control over when intersection events are triggered.
JavaScript
WebKit for Safari 26 beta adds support for Pattern Modifiers in JavaScript’s RegExp objects. Pattern modifiers allow more fine-grained control over the behavior of regular expressions through adding and removing flags within a regular expression.
Safari 26 beta expands support for WebCodecs API by adding AudioEncoder and AudioDecoder. WebCodecs gives developers low-level access to the individual frames of a video stream and chunks of audio. These additions make it possible to encode AudioData objects and decode EncodedAudioChunk objects.
Safari 26 beta now includes several improvements for Media Source API (MSE). It adds support for detachable MediaSource objects to allow for seamless switching between objects attached to a media element. And it adds support for MediaSource prefers DecompressionSession.
WebRTC
WebKit brings multiple updates for WebRTC, adding support for:
Exposing CSRC information for RTCEncodedVideoStream
Speaker Selection API on iOS and iPadOS
Serialisation of RTCEncodedAudioFrame and RTCEncodedVideoFrame
ImageCapture.grabFrame
RTcRtpScriptTransformer.generateKeyFrame to take a rid parameter
RTCEncodedAudioFrame and RTCEncodedVideoFrame constructors
Web Inspector
To inspect a Service Worker you need to open a Web Inspector from Safari’s Develop menu. That’s because the execution context of a Service Worker is independent of the page that installed it. But the action handled by a Service Worker might have already occurred by the time you get to it via the Develop menu. This can happen, for example, with Web Push events where the Service Worker has already handled the incoming push.
To address this, Safari 26 beta introduces automatic inspection and pausing of Service Workers. This is similar to the existing feature for automatic inspection and pausing of JSContexts. To use it, open the Inspect Apps and Devices tool from the Develop menu. Identify the app or Home Screen Web App that uses a Service Worker you want to inspect and, from the three-dots menu, select the option labeled Automatically Inspect New Service Workers. The next time a Service Worker runs in that app, a Web Inspector window will open automatically for it. Use the Automatically Pause New Service Workers option to also pause JavaScript execution in the Service Worker as soon as it’s inspected. This allows you to set breakpoints and step through the code as actions are handled.
Safari 26 beta makes it easier to debug Worker-related memory and performance issues using the Timelines tab in Web Inspector. Breakpoints, profiling data, events, call trees, and heap snapshots are now correctly attributed to each Worker and not its associated page. JavaScript code that runs in a Worker may also call debugger, console.profile, etc to supplement timeline data with application-specific milestones. Lastly, it is now possible to export and import data gathered from Workers in a Timeline recording.
The Elements node tree in Web Inspector now shows a badge labeled Slotted next to nodes that have been inserted into corresponding <slot> nodes within Custom Elements. Click the badge to expand the node tree into the Shadow DOM of the Custom Element and jump to the <slot> node. If there is a correspondence, the <slot> node has a badge labelled Assigned next to it. Click this badge to jump to the node from the light DOM that is slotted here.
The Web Inspector debugger has been updated to provide a more intuitive debugging experience for asynchronous code. You can now step over an await statement as if it were synchronous, meaning the debugger will skip the underlying asynchronous mechanics and move to the next line of code in the function. This simplifies debugging because it allows you to focus on the intended logic of your code, rather than the potentially confusing execution path introduced by await.
Web Extensions
The new web-based Safari Web Extension Packager allows developers to take their existing web extension resources and prepare them for testing in Safari through TestFlight and distribution through the App Store. The tool is available in App Store Connect and uses Xcode Cloud to package the extension resources you provide into a signed app + extension bundle that can be used in Safari on macOS, iOS, iPadOS, and visionOS. Learn more about using the tool in our documentation on developer.apple.com.
Web Extension commands are now shown in the menubar on macOS and iPadOS. On macOS, users can customize the keyboard shortcut associated with a command in Safari Settings.
WebKit API
Several improvements to WebKit API are available now in iOS, iPadOS, macOS, and visionOS beta.
Screen Time support
Local storage and session storage restoration APIs for WKWebView
The ability to applying backdrop-filter to content behind a transparent webview
WebAssembly
As WebAssembly continues to grow in popularity, WebKit has been improving WebAssembly performance across the board. Now, WebAssembly is first evaluated by the in-place interpreter, which allows large WebAssembly code to run even faster.
Privacy
In our continuing efforts to improve privacy and protect users, Safari beta now prevents known fingerprinting scripts from reliably accessing web APIs that may reveal device characteristics, such as screen dimensions, hardware concurrency, the list of voices available through the SpeechSynthesis API, Pay payment capabilities, web audio readback, 2D canvas and more. Safari additionally prevents these scripts from setting long-lived script-written storage such as cookies or LocalStorage. And lastly, Safari prevents known fingerprinting scripts from reading state that could be used for navigational tracking, such as query parameters and document.referrer.
Networking
WebKit now supports <link rel=dns-prefetch> on iOS, iPadOS and visionOS. It gives a hint to the browser to perform a DNS lookup in the background to improve performance. Supported on macOS since Safari 5, it now has improved privacy.
Lockdown Mode
Available on iOS, iPadOS, watchOS, and macOS, Lockdown Mode is an optional, extreme protection that’s designed for the very few individuals who, because of who they are or what they do, might be personally targeted by some of the most sophisticated digital threats. This includes limiting some of what websites can do to ensure the highest level of protection.
Since its beginning, Lockdown Mode disallowed the use of most web fonts. Now instead, web fonts are evaluated by the new Safe Font Parser, and if they pass the evaluation, they are allowed. This means almost all content will be displayed using the specified web fonts in Lockdown Mode.
Website Compatibility
Now in Safari on macOS, iOS, and iPadOS, users can report an issue anytime they are having trouble with a webpage.
If you seem to have trouble that you don’t expect, first try reloading the page. If there’s still a problem, go to the Page menu, where you’ll find “Report a Website issue…” This brings up a quick set of multiple choice questions that provide the key information for us to spot patterns and better ensure a great experience in Safari.
Bug Fixes and more
Along with all of these new features, WebKit for Safari 26 beta includes a plethora of fixes to existing features.
Accessibility
Fixed aria-expanded attribute support on navigation links. (141163086)
Fixed presentational images with empty alt attributes to be ignored by assistive technology, even when additional labeling attributes are set. (146429365)
Fixed <figcaption> within a <figure> element to only contribute to the accessible name of an <img> element if the image lacks other labeling methods like alt, ARIA attributes, or the title attribute. (150597445)
Fixed invalid values for aria-setsize and aria-posinset are now handled according to the updated ARIA specification, to ensure correct accessibility API exposure and predictable behavior for these attributes. (151113693)
CSS
Fixed cursor: pointer not appearing on an <area> element used in conjunction with an <img usemap="..."> element. (74483873)
Fixed grid sizing with inline-size containment and auto-fit columns is incorrectly sized. (108897961)
Fixed content skipped with content-visibility: auto to be findable. (141237620)
Fixed an issue wrapping an SVG at the end of a line when using text-wrap: balance. (141532036)
Fixed @font-face font-family descriptor to not allow a list of values. (142009630)
Fixed the computed value of a float with absolute positioning to be none when there is no box. (144045558)
Fixed buttons to not have align-items: flex-start by default. (146615626)
Fixed @scope to create a style nested context. (148101373)
Fixed changing content-visibility from visible to hidden to repaint correctly. (148273903)
Fixed an issue where float boxes, selections, and carets were incorrectly painted inside skipped subtrees.(148741142)
Fixed incorrect getBoundingClientRect() inside skipped subtree on an out-of-flow positioned box. (148770252)
Fixed making <pre> and other elements use logical margins in the User-Agent stylesheet. (149212392)
Canvas
Fixed re-drawing a canvas with relative width when the parent element is resized. (121996660)
Fixed getContext('2d', { colorSpace: 'display-p3' }) in iOS Simulator. (151188818)
DOM
Fixed the serialization of CDATASection nodes in HTML. (150739105)
Editing
Fixed the selection UI to be clipped in overflow scrolling containers. (9906345)
Fixed selection issues caused by <br> elements between absolute positioned elements. (123637358)
Fixed selection failing to update during auto or keyboard scrolling. (144581646)
Forms
Fixed form associated ElementInternals always reporting a customError when using setValidity. (115681066)
Fixed setValidity of ElementInternals to handle missing optional anchor parameter. (123744294)
Fixed programmatically assigned File objects to display the correct filename in <input> elements, even without a file path. (152048377)
Fixed labels inside <select> elements to behave consistently with other browsers by using standard attribute matching instead of quirk mode handling. (152151133)
JavaScript
Fixed Array.prototype.pop to throw an exception when the array is frozen. (141805240)
Fixed performance of Math.hypot() that was significantly slower than Math.sqrt(). (141821484)
Fixed Array#indexOf and Array#includes to treat +0 and -0 as the same value. (148472519)
Fixed iterator helpers incorrectly closing iterators on early errors. (148774612)
Fixed Iterator.prototype.reduce failing with an undefined initial parameter. (149470140)
Fixed f() = 1 behavior with other engines when not using strict mode. (149831750)
Fixed nested negated classes resulting in incorrect matches. (151000852)
Media
Fixed picture-in-picture to exit when the video element is removed. (123869436)
Fixed MP4 seeking with b-frames to prevent out-of-order frame display by suppressing frames with earlier presentation timestamps following the seek point. (140415210)
Fixed media elements on iPadOS to support the volume being changed by web developers, similar to macOS and visionOS. The :volume-locked pseudo-class can continue to be used for feature detection. (141555604)
Fixed seeking or scrubbing not always seeking to the time requested. (142275903)
Fixed stale audio buffer data after seeking when playing sound through an AudioContext. (146057507)
Fixed subtitle tracks with no srclang to be shown with the correct label. (147722563)
Fixed MediaSession to handle SVG icons with subresources. (150665852)
Fixed MediaCapabilitiesDecodingInfo.configuration to be correctly populated even when .supported is false. (150680756)
Rendering
Fixed an issue to allow images in scroll containers to load when they are near the viewport rather than when they are intersecting the viewport. (118706766)
Fixed a disappearing stretched image in a vertical flexbox layout. (135897530)
Fixed CSS gradient interpolation into regions beyond the first or last color stop. (142738948)
Fixed integrating position-area and self-alignment properties for align-self and justify-self (145889235)
Fixed will-change: view-transition-name to create a stacking context and a backdrop root. (146281670)
Fixed will-change: offset-path to create a stacking context and a containing block. (146292698)
Fixed <datalist> dropdowns not displaying option labels. (146921617)
Fixed the text indicator sometimes getting clipped during a bounce animation. (147602900)
Fixed ancestor bounding box for “disabled” <foreignObject> and <image>. (147455573)
Fixed: Improved handling of SVG images with subresources. (148607855)
Safari View Controller
Fixed lvh and vh viewport units getting incorrectly sized relative to the small viewport in SFSafariViewController. (108380836)
Scrolling
Fixed selection does not update during autoscroll when selecting with a gesture or a mouse. (144744443)
Fixed autoscrolling for smooth scrolling while selecting text. (144900491)
Service Workers
Fixed the ReadableStream cancel method not getting reliably called in Service Worker. (144297119)
Fixed an issue where navigation preload responses incorrectly retained a redirection flag when served from disk cache, causing security check failures during loading. (144571433)
Tables
Fixed table layout to only be triggered when inline-size is not auto. (147636653)
Text
Fixed generating scroll to text fragments around text that contains newlines. (137109344)
Fixed generating text fragments when the selected text starts and ends in different blocks. (137761701)
Fixed bold synthesis to be less aggressive. (138047199)
Fixed Copy Link to Highlight not working when selecting text that is its own block and when that text exists higher up in the document. (144392379)
Fixed selections that start or end in white space not creating text fragments. (145614181)
Fixed <b> and <strong> to use font-weight: bolder to match the Web Specification. (146458131)
URLs
Fixed making URL host and hostname setters handle @ correctly. (146886347)
Web API
Fixed: URL’s protocol setter should forbid switching non-special to special schemes. (82549495)
Fixed event dispatching to be done by the fullscreen rendering update steps. (103209495)
Fixed an overly broad fullscreen exit trigger by restricting it to only text-entry elements gaining focus, preventing non-text input types from causing unexpected fullscreen exits. (136726993)
Fixed WKDownload.originatingFrame of downloads originated without a frame. (145328556)
Fixed fullscreen to use a single queue for event dispatching. (145372389)
Fixed the ProgressEvent members loaded and total to use the double type as per a recent specification change. (146356214)
Fixed Intrinsic Sizing of SVG embedded via <embed> to be invalidated on navigation. (147198632)
Fixed an issue where pending utterances do not receive an error event when speech synthesis is cancelled.(148731039)
Fixed escaping < and > when serializing HTML attribute values. (150520333)
Fixed making the SpeechRecognition interface available only within a secure context. (151240414)
Fixed the option element to not trim the label value and correctly handle an empty label. (151309514)
Web Animations
Fixed CSS scroll-driven animations on pages using requestAnimationFrame to animate correctly after navigating away and back to the page. (141528296)
Fixed computing the time offset as needed when applying accelerated actions. (142604875)
Web Extensions
Fixed a declarativeNetRequest bug that prevents redirects to extension resources. (145569361)
Fixed converting declarativeNetRequest rules so that higher numbers are treated as higher priority. (145570245)
Fixed an issue causing wasm-unsafe-eval to not get parsed as a valid CSP keyword. (147551225)
Fixed permissions.getAll() to return the correct origins if all urls and/or hosts match pattern(s) have been granted. (147872012)
Web Inspector
Fixed pretty-printing CSS to avoid adding a space after the universal selector () when followed by a pseudo-class or pseudo-element, preventing unintended changes to CSS selector behavior. (71544976) Fixed to show a separate overview for each target in the Timelines tab. (146356054)
Fixed a performance issue when blackboxing a large number of sourcemaps. (148116377)
Fixed the debugger to step over an await statement as though it is synchronous code. (149133320)
Fixed parsing sourcemaps asynchronously so that large sourcemaps do not block rendering. (151269154)
Fixed the Timelines tab to consistently display the target’s hierarchical path for JavaScript and Events to prevent confusion when working with multiple targets. (152357197)
WebRTC
Fixed switching from speaker to receiver does not work the first time, but only the second time. (141685006)
Fixed enumerateDevices returning devices as available when permissions are denied. (147313922)
Fixed enumerateDevices to not check for device permission. (148094614)
Fixed WebRTC encoded transform to transfer to the RTC encoded frame array buffer. (148343876)
Fixed RTC encoded frame timestamp should be persistent. (148580865)
Fixed the configurationchange event to fire when a microphone’s audio unit changes its echo cancellation mode, ensuring web pages are notified of such changes to update track settings accordingly. (150770940)
Try out Safari 26 beta
You can test Safari 26 beta by installing the beta of macOS Tahoe 26, iOS 26, iPadOS 26 or visionOS 26. Or if you’d like, try out Safari 26 beta on macOS Sequoia or macOS Sonoma by downloading Safari 26 beta, once it’s available. (Sign in using a free Apple ID to download. Installing Safari 26 beta on macOS Sequoia or macOS Sonoma will replace your existing version of Safari with no way to revert to an earlier version.)
We love hearing from you. To share your thoughts, find our web evangelists online: Jen Simmons on Bluesky / Mastodon, Saron Yitbarek on BlueSky, and Jon Davis on Bluesky / Mastodon. You can follow WebKit on LinkedIn. If you run into any issues, we welcome your feedback on Safari UI (learn more about filing Feedback), or your WebKit bug report about web technologies or Web Inspector. If you run into a website that isn’t working as expected, please file a report at webcompat.com. Filing issues really does make a difference.
Learn how the latest web technologies in Safari and WebKit can help you create incredible experiences. We’ll highlight different CSS features and how they work, including scroll driven animation, cross document view transitions, and anchor positioning. We’ll also explore new media support across audio, video, images, and icons.
Discover the latest spatial features for the web on visionOS. We’ll cover how to display inline 3D models with the brand new HTML model element. And we’ll share powerful features, including model lighting, interactions, and animations. Learn how to embed newly supported immersive media on your web site, such as 360-degree video and Apple Immersive Video. And get a sneak peek at adding a custom environment to your web pages.
Learn how Declarative Web Push can help you deliver notifications more reliably. Find out how to build on existing standards to be more efficient and transparent by design while retaining backwards compatibility with original Web Push.
Discover how iOS, iPadOS, macOS, and visionOS enhance passkeys. We’ll explore key updates including: the new account creation API for streamlined sign-up, keeping passkeys up-to-date, new ways to drive passkey upgrades through automatic passkey upgrades and passkey management endpoints, and the secure import/export of passkeys. Learn how these improvements enhance user experience and security, and how to implement these updates in your apps to provide a smoother, more secure authentication experience. To get the most out of this video, first watch Meet passkeys from WWDC22.
Learn how Digital Credentials can enhance online identity verification flows. We’ll cover how websites can integrate the Digital Credentials API to enable requesting information from IDs in Wallet. We’ll also explore how apps can provide their own identity documents for online verification using the new IdentityDocumentServices framework.
Learn how the WebGPU API provides safe access to GPU devices for graphics and general-purpose computation. We’ll also explore the WGSL shading language to write GPU programs. And we’ll dive into best practices to achieve optimal performance while using minimal power across desktop and mobile devices.
Discover how you can use WebKit to effortlessly integrate web content into your SwiftUI apps. Learn how to load and display web content, communicate with webpages, and more.
Check out this week’s episode of Shop Talk Show where we appeared to talk about Declarative Web Push, the future of form control styling, color contrast algorithms, accessibility standards, enhancements in color picker functionality, typography improvements and more.
The Web Engines Hackfest 2025 is kicking off next Monday in A Coruña and among
all the interesting talks and
sessions about
different engines, there are a few that can be interesting to people involved
one way or another with WebKitGTK and WPE:
“Multimedia in
WebKit”, by Philippe
Normand (Tuesday 3rd at 12:00 CEST), will focus on the current status and
future plans for the multimedia stack in WebKit.
All talks will be live streamed and a Jitsi Meet link will be available for
those interested in participating remotely. You can find all the details at
webengineshackfest.org.
Safari Technology Preview Release 220 is now available for download for macOS Sequoia and macOS Sonoma. If you already have Safari Technology Preview installed, you can update it in System Settings under General → Software Update.
Added support for field-sizing to override the default sizing behavior of form elements and adjust size to fit their contents. (295370@main) (151949208)
Resolved Issues
Fixed grid sizing with inline-size containment and auto-fit columns is incorrectly sized. (295023@main) (108897961)
Fixed a bug where an anchor-positioned element does not properly render when it’s initially hidden from view, then shown. (294924@main) (148608785)
DOM
Resolved Issues
Fixed the serialization of CDATASection nodes in HTML. (294547@main) (150739105)
JavaScript
New Features
Added support for @@dispose and @@asyncDispose from the Explicit Resource Management Proposal behind runtime flag. (294592@main) (150816114)
Added support for SuppressedError from the Explicit Resource Management Proposal behind runtime flag. (294774@main) (151132111)
Added support for DisposableStack constructor from the Explicit Resource Management Proposal behind runtime flag. (294880@main) (151280591)
Media
Resolved Issues
Fixed MediaSession to handle SVG icons with subresources. (294499@main) (150665852)
Fixed MediaCapabilitiesDecodingInfo.configuration to be correctly populated even when .supported is false. (294957@main) (150680756)
Rendering
Resolved Issues
Fixed invisible <audio> controls when transformed due to incorrect coordinate space calculations for clipped child elements. (294694@main) (150526971)
Fixed centering text for <input type=button> elements with display: flex. (294785@main) (151148821)
Fixed showing a resize cursor even when text overlaps the resize control. (294907@main) (151309503)
Web Animations
Resolved Issues
Fixed CSS scroll-driven animations on pages using requestAnimationFrame to animate correctly after navigating away and back to the page. (294889@main) (141528296)
Web API
Resolved Issues
Fixed making the SpeechRecognition interface available only within a secure context. (294887@main) (151240414)
Web Inspector
Resolved Issues
Fixed parsing sourcemaps asynchronously so that large sourcemaps do not block rendering. (294875@main) (151269154)
WebRTC
Resolved Issues
Fixed the configurationchange event to fire when a microphone’s audio unit changes its echo cancellation mode, ensuring web pages are notified of such changes to update track settings accordingly. (294839@main) (150770940)
Update on what happened in WebKit in the week from May 19 to May 26.
This week saw updates on the Android version of WPE, the introduction
of a new mechanism to support memory-mappable buffers which can lead
to better performance, a new gamepad API to WPE, and other improvements.
Cross-Port 🐱
Implemented support for the new 'request-close' command for dialog elements.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Added support for using the GDB JIT API when dynamically generating code in JSC.
Graphics 🖼️
Added support for memory-mappable GPU buffers. This mechanism allows to allocate linear textures that can be used from OpenGL, and memory-mapped into CPU-accessible memory. This allows to update the pixel data directly, bypassing the usual glCopyTexSubImage2D logic that may introduce implicit synchronization / perform staging copies / etc. (driver-dependant).
WPE WebKit 📟
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
Landed a patch to add a gamepads API to WPE Platform with an optional default implementation using libmanette.
Igalia worked with Savant Systems to bring a seamless, high-performance music experience to its smart home ecosystem. By enhancing WPE WebKit with critical backported patches, developing a custom Widevine CDM, and engineering a JavaScript D-Bus bridge, WPE WebKit was adapted to ensure robust and secure media playback directly within Savant’s platform.
Delivering a tightly integrated music experience in a smart home environment required overcoming significant technical challenges. To achieve this, WPE WebKit’s capabilities were streamlined to enable a fluid interface and reliable communication between the browser and the music process that powers a third-party music integration.
With deep expertise in browser technology and embedded systems, Igalia was able to help Savant implement a tailored WPE WebKit integration, optimizing performance while maintaining security and responsiveness. The result is a cutting-edge solution that enhances user experience and supports Savant’s commitment to innovation in smart home entertainment.
Update on what happened in WebKit in the week from May 12 to May 19.
This week focused on infrastructure improvements, new releases that
include security fixes, and featured external projects that use the
GTK and WPE ports.
Cross-Port 🐱
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
Fixed
a reference cycle in the mediastreamsrc element, which prevented its disposal.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Added an internal class that will be
used to represent Temporal Duration objects in a way that allows for more
precise calculations. This is not a user-visible change, but will enable future
PRs to advance Temporal support in JSC towards completion.
WPE WebKit 📟
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
Added
an initial demo application to the GTK4 WPEPlatform implementation.
Releases 📦️
WebKitGTK
2.48.2 and
WPE WebKit 2.48.2 have
been released. These are paired with a security advisory (WSA-2025-0004:
GTK,
WPE), and therefore it is
advised to update.
On top of security fixes, these release also include correctness fixes, and
support for CSS Overscroll
Behaviour
is now enabled by default.
Community & Events 🤝
GNOME Web has
gained a
preferences page that allows toggling WebKit features at run-time. Tech Preview
builds of the browser will show the settings page by default, while in regular
releases it is hidden and may be enabled with the following command:
gsettings set org.gnome.Epiphany.ui webkit-features-page true
This should allow frontend developers to test upcoming features more easily. Note that the settings for WebKit features are not persistent, and they will be reset to their default state on every launch.
Infrastructure 🏗️
Landed an improvement to error
reporting in the script within WebKit that runs test262 JavaScript tests.
The WebKit Test Runner (WKTR) will no longer
crash if invalid UTF-8 sequences
are written to the standard error stream, (e.g. from 3rd party libraries'
debugging options.
Experimentation is ongoing to un-inline String::find(), which saves ~50 KiB
in the resulting binary size worth of repeated implementations of SIMD “find
character in UTF-16” and “find character in UTF-32” algorithms. Notably, the
algorithm for “find character in ASCII string” was not even part of the
inlining.
Added the LLVM
repository to the
WebKit container SDK. Now it is possible to easily install Clang 20.x with
wkdev-setup-default-clang --version=20.
Figured out that a performance bug related to jump threading optimization in
Clang 18 resulted in a bottleneck adding up to five minutes of build time in
the container SDK. This may be fixed by updating to Clang 20.x.
Update on what happened in WebKit in the week from May 5 to May 12.
This week saw one more feature enabled by default, additional support to
track memory allocations, continued work on multimedia and WebAssembly.
Cross-Port 🐱
The Media Capabilities API is now enabled by default. It was previously available as a run-time option in the WPE/WebKitGTK API (WebKitSettings:enable-media-capabilities), so this is just a default tweak.
Landed a change that integrates malloc heap breakdown functionality with non-Apple ports. It works similarly to Apple's one yet in case of non-Apple ports the per-heap memory allocation statistics are printed to stdout periodically for now. In the future this functionality will be integrated with Sysprof.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
Support for WebRTC RTP header extensions was improved, a RTP header extension for video orientation metadata handling was introduced and several simulcast tests are now passing
Progress is ongoing on resumable player suspension, which will eventually allow us to handle websites with lots of simultaneous media elements better in the GStreamer ports, but this is a complex task.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
The in-place Wasm interpreter (IPInt) port to 32-bits has seen some more work.
Fixed a bug in OMG caused by divergence with the 64-bit version. Further syncing is underway.
Releases 📦️
Michael Catanzaro has published a writeup on his blog about how the WebKitGTK API versions have changed over time.
Infrastructure 🏗️
Landed some improvements in the WebKit container SDK for Linux, particularly in error handling.
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
The GstWPE2 GStreamer plugin landed in GStreamer
main,
it makes use of the WPEPlatform API. It will ship in GStreamer 1.28. Compared
to GstWPE1 it provides the same features, but improved support for NVIDIA
GPUs. The main regression is lack of audio support, which is work-in-progress,
both on the WPE and GStreamer sides.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Work on enabling the in-place Wasm interpreter (IPInt) on 32-bits has progressednicely
The JSC tests runner can now guard against a pathological failure mode.
In JavaScriptCore's implementation of
Temporal,
Tim Chevalier fixed the parsing of RFC
9557 annotations in date
strings to work according to the standard. So now syntactically valid but
unknown annotations [foo=bar] are correctly ignored, and the ! flag in an
annotation is handled correctly. Philip Chimento expanded the test suite
around this feature and fixed a couple of crashes in Temporal.
Math.hypot(x, y, z) received a fix for a corner case.
WPE WebKit 📟
WPE now uses the new pasteboard API, aligning it with the GTK port, and enabling features that were previously disabled. Note that the new features work only with WPEPlatform, because libwpe-based backends are limited to access clipboard text items.
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
Platform backends may add their own clipboard handling, with the Wayland one being the first one to, using wl_data_device_manager.
This continues the effort to close the feature gap between the “traditional” libwpe-based WPE backends and the new WPEPlatform ones.
Community & Events 🤝
Carlos García has published a blog post about the optimizations introduced in
the WPE and GTK WebKit
ports
since the introduction of Skia replacing Cairo for 2D rendering. Plus, there
are some hints about what is coming next.
In my previous post, when I introduced the switch to Skia for 2D rendering, I explained that we replaced Cairo with Skia keeping mostly the same architecture. This alone was an important improvement in performance, but still the graphics implementation was designed for Cairo and CPU rendering. Once we considered the switch to Skia as stable, we started to work on changes to take more advantage of Skia and GPU rendering to improve the performance even more. In this post I’m going to present some of those improvements and other not directly related to Skia and GPU rendering.
Explicit fence support
This is related to the DMA-BUF renderer used by the GTK port and WPE when using the new API. The composited buffer is shared as a DMA-BUF between the web and UI processes. Once the web process finished the composition we created a fence and waited for it, to make sure that when the UI process was notified that the composition was done the buffer was actually ready. This approach was safe, but slow. In 281640@main we introduced support for explicit fencing to the WPE port. When possible, an exportable fence is created, so that instead of waiting for it immediately, we export it as a file descriptor that is sent to the UI process as part of the message that notifies that a new frame has been composited. This unblocks the web process as soon as composition is done. When supported by the platform, for example in WPE under Wayland when the zwp_linux_explicit_synchronization_v1 protocol is available, the fence file descriptor is passed to the platform implementation. Otherwise, the UI process asynchronously waits for the fence by polling the file descriptor before passing the buffer to the platform. This is what we always do in the GTK port since 281744@main. This change improved the score of all MotionMark tests, see for example multiply.
Enable MSAA when available
In 282223@main we enabled the support for MSAA when possible in the WPE port only, because this is more important for embedded devices where we use 4 samples providing good enough quality with a better performance. This change improved the Motion Mark tests that use 2D canvas like canvas arcs, paths and canvas lines. You can see here the change in paths when run in a RaspberryPi 4 with WPE 64 bits.
Avoid textures copies in accelerated 2D canvas
As I also explained in the previous post, when 2D canvas is accelerated we now use a dedicated layer that renders into a texture that is copied to be passed to the compositor. In 283460@main we changed the implementation to use a CoordinatedPlatformLayerBufferNativeImage to handle the canvas texture and avoid the copy, directly passing the texture to the compositor. This improved the MotionMark tests that use 2D canvas. See canvas arcs, for example.
Introduce threaded GPU painting mode
In the initial implementation of the GPU rendering mode, layers were painted in the main thread. In 287060@main we moved the rendering task to a dedicated thread when using the GPU, with the same threaded rendering architecture we have always used for CPU rendering, but limited to 1 worker thread. This improved the performance of several MotionMark tests like images, suits and multiply. See images.
Update default GPU thread settings
Parallelization is not so important for GPU rendering compared to CPU, but still we realized that we got better results by increasing a bit the amount of worker threads when doing GPU rendering. In 290781@main we increased the limit of GPU worker threads to 2 for systems with at least 4 CPU cores. This improved mainly images and suits in MotionMark. See suits.
Hybrid threaded CPU+GPU rendering mode
We had either GPU or CPU worker threads for layer rendering. In systems with 4 CPU cores or more we now have 2 GPU worker threads. When those 2 threads are busy rendering, why not using the CPU to render other pending tiles? And the same applies when doing CPU rendering, when all workers are busy, could we use the GPU to render other pending tasks? We tried and turned out to be a good idea, especially in embedded devices. In 291106@main we introduced the hybrid mode, giving priority to GPU or CPU workers depending on the default rendering mode, and also taking into account special cases like on HiDPI, where we are always scaling, and we always prefer the GPU. This improved multiply, images and suits. See images.
Use Skia API for display list implementation
When rendering with Cairo and threaded rendering enabled we use our own implementation of display lists specific to Cairo. When switching to Skia we thought it was a good idea to use the WebCore display list implementation instead, since it’s cross-platform implementation shared with other ports. But we realized this implementation is not yet ready to support multiple threads, because it holds references to WebCore objects that are not thread safe. Main thread might change those objects before they have been processed by painting threads. So, we decided to try to use the Skia API (SkPicture) that supports recording in the main thread and replaying from worker threads. In 292639@main we replaced the WebCore display list usage by SkPicture. This was expected to be a neutral change in terms of performance but it surprisingly improved several MotionMark tests like leaves, multiply and suits. See leaves.
Use Damage to track the dirty region of GraphicsLayer
Every time there’s a change in a GraphicsLayer and it needs to be repainted, it’s notified and the area that changed is included so that we only render the parts of the layer that changed. That’s what we call the layer dirty region. It can happen that when there are many small updates in a layer we end up with lots of dirty regions on every layer flush. We used to have a limit of 32 dirty regions per layer, so that when more than 32 are added we just united them into the first dirty area. This limit was removed because we always unite the dirty areas for the same tiles when processing the updates to prepare the rendering tasks. However, we also tried to avoid handling the same dirty region twice, so every time a new dirty region was added we iterated the existing regions to check if it was already present. Without the 32 regions limit that means we ended up iterating a potentially very long list on every dirty region addition. The damage propagation feature uses a Damage class to efficiently handle dirty regions, so we thought we could reuse it to track the layer dirty region, bringing back the limit but uniting in a more efficient way than using always the first dirty area of the list. It also allowed to remove check for duplicated area in the list. This change was added in 292747@main and improved the performance of MotionMark leaves and multiply tests. See leaves.
Record all dirty tiles of a layer once
After the switch to use SkPicture for the display list implementation, we realized that this API would also allow to record the graphics layer once, using the bounding box of the dirty region, and then replay multiple times on worker threads for every dirty tile. Recording can be a very heavy operation, specially when there are shadows or filters, and it was always done for every tile due to the limitations of the previous display list implementation. In 292929@main we introduced the change with improvements in MotionMark leaves and multiply tests. See multiply.
MotionMark results
I’ve shown here the improvements of these changes in some of the MotionMark tests. I have to say that some of those changes also introduced small regressions in other tests, but the global improvement is still noticeable. Here is a table with the scores of all tests before these improvements and current main branch run by WPE MiniBrowser in a RaspberryPi 4 (64bit).
Test
Score July 2024
Score April 2025
Multiply
501.17
684.23
Canvas arcs
140.24
828.05
Canvas lines
1613.93
3086.60
Paths
375.52
4255.65
Leaves
319.31
470.78
Images
162.69
267.78
Suits
232.91
445.80
Design
33.79
64.06
What’s next?
There’s still quite a lot of room for improvement, so we are already working on other features and exploring ideas to continue improving the performance. Some of those are:
Damage tracking: this feature is already present, but disabled by default because it’s still work in progress. We currently use the damage information to only paint the areas of every layer that changed. But then we always compose a whole frame inside WebKit that is passed to the UI process to be presented on screen. It’s possible to use the damage information to improve both, the composition inside WebKit and the presentation of the composited frame on the screen. For more details about this feature read Pawel’s awesome blog post about it.
Use DMA-BUF for tile textures to improve pixel transfer operations: We currently use DMA-BUF buffers to share the composited frame between the web and UI process. We are now exploring the idea of using DMA-BUF also for the textures used by the WebKit compositor to generate the frame. This would allow to improve the performance of pixel transfer operations, for example when doing CPU rendering we need to upload the dirty regions from main memory to a compositor texture on every composition. With DMA-BUF backed textures we can map the buffer into main memory and paint with the CPU directly into the mapped buffer.
Compositor synchronization: We plan to try to improve the synchronization of the WebKit compositor with the system vblank and the different sources of composition (painted layers, video layers, CSS animations, WebGL, etc.)
Damage propagation is an optional WPE/GTK WebKit feature that — when enabled — reduces browser’s GPU utilization at the expense of increased CPU and memory utilization. It’s very useful especially in the context of low- and mid-end
embedded devices, where GPUs are most often not too powerful and thus become a performance bottleneck in many applications.
In computer graphics, the damage term is usually used in the context of repeatable rendering and means essentially “the region of a rendered scene that changed and requires repainting”.
In the context of WebKit, the above definition may be specialized a bit as WebKit’s rendering engine is about rendering web content to frames (passed further to the platform) in response to changes within a web page.
Thus the definition of WebKit’s damage refers, more specifically, to “the region of web page view that changed since previous frame and requires repainting”.
On the implementation level, the damage is almost always a collection of rectangles that cover the changed region. This is exactly the case for WPE and GTK WebKit ports.
To better understand what the above means, it’s recommended to carefully examine the below screenshot of GTK MiniBrowser as it depicts the rendering of the poster circle demo
with the damage visualizer activated:
In the image above, one can see the following elements:
the web page view — marked with a rectangle stroked to magenta color,
the damage — marked with red rectangles,
the browser elements — everything that lays above the rectangle stroked to a magenta color.
What the above image depicts in practice, is that during that particular frame rendering, the area highlighted red (the damage) has changed and needs to be repainted. Thus — as expected — only the moving parts of the demo require repainting.
It’s also worth emphasizing that in that case, it’s also easy to see how small fraction of the web page view requires repainting. Hence one can imagine the gains from the reduced amount of painting.
Normally, the job of the rendering engine is to paint the contents of a web page view to a frame (or buffer in more general terms) and provide such rendering result to the platform on every scene rendering iteration —
which usually is 60 times per second.
Without the damage propagation feature, the whole frame is marked as changed (the whole web page view) always. Therefore, the platform has to perform the full update of the pixels it has 60 times per second.
While in most of the use cases, the above approach is good enough, in the case of embedded devices with less powerful GPUs, this can be optimized. The basic idea is to produce the frame along with the damage information i.e. a hint for
the platform on what changed within the produced frame. With the damage provided (usually as an array of rectangles), the platform can optimize a lot of its operations as — effectively — it can
perform just a partial update of its internal memory. In practice, this usually means that fewer pixels require updating on the screen.
For the above optimization to work, the damage has to be calculated by the rendering engine for each frame and then propagated along with the produced frame up to its final destination. Thus the damage propagation can be summarized
as continuous damage calculation and propagation throughout the web engine.
Once the general idea has been highlighted, it’s possible to examine the damage propagation in more detail. Before reading further, however, it’s highly recommended for the reader to go carefully through the
famous “WPE Graphics architecture” article that gives a good overview of the WebKit graphics pipeline in general and which introduces the basic terminology
used in that context.
The information on the visual changes within the web page view has to travel a very long way before it reaches the final destination. As it traverses the thread and process boundaries in an orderly manner, it can be summarized
as forming a pipeline within the broader graphics pipeline. The image below presents an overview of such damage propagation pipeline:
This pipeline starts with the changes to the web page view visual state (RenderTree) being triggered by one of many possible sources. Such sources may include:
User interactions — e.g. moving mouse cursor around (and hence hovering elements etc.), typing text using keyboard etc.
Web API usage — e.g. the web page changing DOM, CSS etc.
multimedia — e.g. the media player in a playing state,
and many others.
Once the changes are induced for certain RenderObjects, their visual impact is calculated and encoded as rectangles called dirty as they
require re-painting within a GraphicsLayer the particular RenderObject
maps to. At this point, the visual changes may simply be called layer damage as the dirty rectangles are stored in the layer coordinate space and as they describe what changed within that certain layer since the last frame was rendered.
The next step in the pipeline is passing the layer damage of each GraphicsLayer
(GraphicsLayerCoordinated) to the WebKit’s compositor. This is done along with any other layer
updates and is mostly covered by the CoordinatedPlatformLayer.
The “coordinated” prefix of that name is not without meaning. As threaded accelerated compositing is usually used nowadays, passing the layer damage to the WebKit’s compositor must be coordinated between the main thread and
the compositor thread.
When the layer damage of each layer is passed to the WebKit’s compositor, it’s stored in the TextureMapperLayer that corresponds to the given
layer’s CoordinatedPlatformLayer. With that — and with all other layer-level updates — the
WebKit’s compositor can start computing the frame damage i.e. damage that is the final damage to be passed to the very end of the pipeline.
The first step to building frame damage is to process the layer updates. Layer updates describe changes of various layer properties such as size, position, transform, opacity, background color, etc. Many of those updates
have a visual impact on the final frame, therefore a portion of frame damage must be inferred from those changes. For example, a layer’s transform change that effectively changes the layer position means that the layer
visually disappears from one place and appears in the other. Thus the frame damage has to account for both the layer’s old and new position.
Once the layer updates are processed, WebKit’s compositor has a full set of information to take the layer damage of each layer into account. Thus in the second step, WebKit’s compositor traverses the tree formed out of
TextureMapperLayer objects and collects their layer damages. Once the layer damage of a certain layer
is collected, it’s transformed from the layer coordinate space into a global coordinate space so that it can be added to the frame damage directly.
After those two steps, the frame damage is ready. At this point, it can be used for a couple of extra use cases:
for WebKit’s compositor itself to perform some extra optimizations — as will be explained in the WebKit’s compositor optimizations section,
for layout tests.
Eventually — regardless of extra uses — the WebKit’s compositor composes the frame and sends it (a handle to it) to the UI Process along with frame damage using the IPC mechanism.
In the UI process, there are basically two options determining frame damage destiny — it can be either consumed or ignored — depending on the platform-facing implementation. At the moment of writing:
At the moment of writing, the damage propagation feature is run-time-disabled by default (PropagateDamagingInformation feature flag) and compile-time enabled by default for GTK and WPE (with new platform API) ports.
Overall, the feature works pretty well in the majority of real-world scenarios. However, there are still some uncovered code paths that lead to visual glitches. Therefore it’s fair to say the feature is still a work in progress.
The work, however, is pretty advanced. Moreover, the feature is set to a testable state and thus it’s active throughout all the layout test runs on CI.
Not only the feature is tested by every layout test that tests any kind of rendering, but it also has quite a lot of dedicated layout tests.
Not to mention the unit tests covering the Damage class.
In terms of functionalities, when the feature is enabled it:
activates the damage propagation pipeline and hence propagates the damage up to the platform,
When the feature is enabled, the main goal is to activate the damage propagation pipeline so that eventually the damage can be provided to the platform. However, in reality, a substantial part of the pipeline is always active
regardless of the features being enabled or compiled. This part of the pipeline ends before the damage reaches
CoordinatedPlatformLayer and is always active because it was used for layer-level optimizations for a long time.
More specifically — this part of the pipeline existed long before the damage propagation feature and was using layer damage to optimize the layer painting to the intermediate surfaces.
Because of the above, when the feature is enabled, only the part of the pipeline that starts with CoordinatedPlatformLayer
is activated. It is, however, still a significant portion of the pipeline and therefore it implies additional CPU/memory costs.
When the feature is activated and the damage flows through the WebKit’s compositor, it creates a unique opportunity for the compositor to utilize that information and reduce the amount of painting/compositing it has to perform.
At the moment of writing, the GTK/WPE WebKit’s compositor is using the damage to optimize the following:
to apply global glScissor to define the smallest possible clipping rect for all the painting it does — thus reducing the amount of painting,
to reduce the amount of painting when compositing the tiles of the layers using tiled backing stores.
Detailed descriptions of the above optimizations are well beyond the scope of this article and thus will be provided in one of the next articles on the subject of damage propagation.
As mentioned in the above sections, the feature only works in the GTK and the new-platform-API-powered WPE ports. This means that:
In the case of GTK, one can use MiniBrowser or any up-to-date GTK-WebKit-derived browser to test the feature.
In the case of WPE with the new WPE platform API the cog browser cannot be used as it uses the old API. Therefore, one has to use MiniBrowser
with the --use-wpe-platform-api argument to activate the new WPE platform API.
Moreover, as the feature is run-time-disabled by default, it’s necessary to activate it. In the case of MiniBrowser, the switch is --features=+PropagateDamagingInformation.
For quick testing, it’s highly recommended to use the latest revision of WebKit@main with wkdev SDK container and with GTK port.
Assuming one has set up the container, the commands to build and run GTK’s MiniBrowser are as follows:
It’s also worth mentioning that WEBKIT_SHOW_DAMAGE=1 environment variable disables damage-driven GTK/WPE WebKit’s compositor optimizations and therefore some glitches that are seen without the envvar, may not be seen
when it is set. The URL to this presentation is a great example to explore various glitches that are yet to be fixed. To trigger them, it’s enough to navigate
around the presentation using top/right/down/left arrows.
This article was meant to scratch the surface of the broad, damage propagation topic. While it focused mostly on introducing basic terminology and describing the damage propagation pipeline in more detail,
it briefly mentioned or skipped completely the following aspects of the feature:
the problem of storing the damage information efficiently,
the damage-driven optimizations of the GTK/WPE WebKit’s compositor,
the most common use cases for the feature,
the benchmark results on desktop-class and embedded devices.
Therefore, in the next articles, the above topics will be examined to a larger extent.
The new WPE platform API is still not released and thus it’s not yet officially announced. Some information on it, however, is provided by
this presentation prepared for a WebKit contributors meeting.
The platform that the WebKit renders to depends on the WebKit port:
in case of GTK port, the platform is GTK so the rendering is done to GtkWidget,
in case of WPE port with new WPE platform API, the platform is one of the following:
wayland — in that case rendering is done to the system’s compositor,
DRM — in that case rendering is done directly to the screen,
headless — in that case rendering is usually done into memory buffer.
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
On the WebRTC front, basic support for Rapid Synchronization was added, along with a couple of spec coverage improvements (https://commits.webkit.org/293567@main, https://commits.webkit.org/293569@main).
Dispatch a "canceled" error event for all queued utterances in case of SpeechSynthesis.
Support for the Camera desktop portal was added recently, it will benefit mostly Flatpak apps using WebKitGTK, such as GNOME Web, for access to capture devices, which is a requirement for WebRTC support.
JavaScriptCore 🐟
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Work continued on porting the in-place wasm interpreter (IPInt) to 32-bits.
We have been working on bringing the Temporal implementation in JSC up to the current spec, and a step towards that goal was implemented in WebKit PR #43849. This PR changes how calendar annotation key parsing works; it doesn't change anything observable, but sets the groundwork for parsing calendar critical flags and unknown annotations.
Releases 📦️
The recent releases of WebKitGTK and WPE WebKit 2.48 introduced a number of improvements to performance, reduced resource usage, better support for web platform features and standards, multimedia, and more!
Read more about these updates in the freshly published articles for WebKitGTK, and WPE WebKit.
Pawel Lampe published a blog post on the damage propagation feature. This feature reduces browser's GPU utilization at the expense of increased CPU and memory utilization in the WPE and GTK WebKit ports.
Our efforts to bring GstWebRTC support to WebKitGTK and WPEWebKit also include direct contributions to GStreamer. We recently improved WebRTC spec compliance in webrtcbin, by making the SDP mid attribute optional in offers and answers.
The WPE WebKit team has been working hard during the past six months and has recently released version 2.48 of the WPE port of WebKit. As is now tradition, here is an overview of the most important changes in this new stable release series.
Graphics and Rendering
The work on the graphics pipeline of WebKit continues, and a lot of improvements, refactorings, bug fixes, and optimizations have happened under the hood. These changes bring both performance and rendering improvements, and are too many to list individually. Nonetheless, there are a number of interesting changes.
GPU Worker Threads
When GPU rendering with Skia is in use, tiles will be rendered in worker threads, which has a positive impact on performance. Threads were already used when using the CPU for rendering. Note that GPU usage for rendering is not yet the default in the WPE port, but may be enabled setting WEBKIT_SKIA_ENABLE_CPU_RENDERING=0 in the environment before running programs that use WPE WebKit.
Canvas Improvements
The CanvasRenderingContext2DputImageData() and getImageData() methods have been optimized by preventing unnecessary buffer copies, resulting in improved performance and reduced memory usage.
CSS 3D Transforms
There have been several improvements handling elements that use preserve-3dCSS transforms. On top of a modest performance improvement, the changes fixed rendering issues, making the implementation compliant with the specification.
Damage Tracking
This release gained experimental support for collecting “damage” information, which tracks which parts of Web content produce visual changes in the displayed output. This information is then taken into account to reuse existing graphics buffers and repaint only those parts that need to be modified. This results better performance and less resource usage.
Note that this feature is disabled by default and may be previewed toggling the PropagateDamagingInformation feature flag.
GPU Process Beginnings
A new “GPU process” is now always built, but its usage is disabled by default at runtime. This is an experimental feature that can be toggled via the UseGPUProcessForWebGL feature flag, and as the name implies at the moment this new auxiliary process only supports handling WebGL content.
The GPU process is a new addition to WebKit’s multiprocess model, in which isolated processes are responsible for different tasks: the GPU process will eventually be in charge of most tasks that make use of the graphics processing unit, in order to improve security by separating graphics handling from Web content and data access. At the same time, graphics-intensive work does not interfere with Web content handling, which may bring potential performance improvements in the future.
Multimedia
The MediaRecorder backend gained support for the WebM format and audio bitrate configuration. WebM usage requires GStreamer 1.24.9 or newer.
Video handling using the WebCodecs API no longer ignores the prefer-hardware option. It is used as a hint to attempt using hardware-accelerated GStreamer components. If that fails, software based codecs will be used as fallback.
The Web Speech API gained a new synthesis backend, using libspiel. The existing FLite-based backend is still chosen by default because the dependency is readily available in most distributions, but setting USE_SPIEL=ON at build time is recommended where libspiel may be available.
The GStreamer-GL sink can now handle DMA-BUF memory buffers, replacing the DMA-BUF sink in this way.
The WPEPlatform library is a completely new API which changes how WPE embedding API works. The aim is to make both developing WPE backends and user applications more approachable and idiomatic using GLib and GObject conventions. Inspiration has been drawn from the Cog API. A preview version is shipped along in 2.48, and as such it needs to be explicitly enabled at build time with ENABLE_WPE_PLATFORM=ON. The API may still change and applications developed using WPEPlatform are likely to need changes with future WPE WebKit releases.
Web Platform
The list of Web Platform features that are newly available in 2.48 is considerably long, and includes the following highlights:
Support for CSS progress(), media-progress() and container-progress() functions—all part of the CSS, behind runtime flags CSSMediaProgressFunction and CSSContainerProgressFunction, respectively.
Packaging
The Web Inspector resources are no longer built into a shared library, but as a GResource bundle file. This avoids usage of the dynamic linker and allows mapping the file in memory, which brings improved resource usage.
Packagers and distributors might need some adaptation of their build infrastructure in cases where the Web Inspector resources have some ad-hoc handling. Typical cases are avoiding installation in production builds for embedded devices, or as an optional component for development builds.
For example, using the default build configuration, the file with the resources inside the installation prefix will be share/wpe-webkit-2.0/inspector.gresource, instead of the old lib/wpe-webkit-2.0/libWPEWebInspectorResources.so library.
Other Noteworthy Changes
The minimum required ICU version is now 70.1.
Reading of Remote Web Inspector protocol messages was optimized, resulting in a considerable speed-up for large messages.
The WPE WebKit team is already working on the 2.50 release, which is planned for September. In the meantime, you can expect stable updates for the 2.48 series through the usual channels.
Update on what happened in WebKit in the week from March 31 to April 7.
Cross-Port 🐱
Graphics 🖼️
By default we divide layers that need to be painted into 512x512 tiles, and
only paint the tiles that have changed. We record each layer/tile combination
into a SkPicture and replay the painting commands in worker threads, either
on the CPU or the GPU. A change was
landed to improve the algorithm,
by recording the changed area of each layer into a single SkPicture, and for
each tile replay the same picture, but clipped to the tile dimensions and
position.
WPE WebKit 📟
WPE Platform API 🧩
New, modern platform API that supersedes usage of libwpe and WPE backends.
A WPE Platform-based implementation of Media Queries' Interaction Media
Features, supporting
pointer and hover-related queries, has
landed in WPE WebKit.
When using the Wayland backend, this change exposes the current state of
pointing devices (mouse and touchscreen), dynamically reacting to changes such
as plugging or unplugging. When the new WPEPlatform API is not used, the
previous behaviour, defined at build time, is still used.
Adaptation of WPE WebKit targeting the Android operating system.
A number of fixes havebeenmerged to fix and improve building WPE WebKit for Android. This is part of an ongoing effort to make it possible to build WPE-Android using upstream WebKit without needing additional patches.
The example MiniBrowser included with WPE-Android has beenfixed to handle edge-to-edge layouts on Android 15.
From SmartTVs to light bulbs and cameras, smart devices are not hard to find in homes these days. Glancr’s smart mirror is a device that seamlessly integrates digital functionality into everyday life. Powered by its custom operating system mirr.OS, Glancr puts the Web at the forefront, allowing users to see all the information that matters to them in a customizable interface, right on a mirror. Besides being useful in smart home scenarios, Glancr can also expand the possibilities in other use cases in the industry, such as digital signage, point-of-sale devices, or even the healthcare industry.
WPE WebKit empowers mirr.OS to efficiently run and render interactive widgets and applications, ensuring a fluid and responsive user experience at the same time that enables mirr.OS to leverage the power of the Web Platform. This allows developers to create rich, web-based interfaces tailored to the smart mirror’s unique requirements, in order to deliver a seamless and visually compelling interaction layer for users at the same time it bridges the gap between digital functionality and aesthetic appeal.
Doing a 32-bit build on ARM64 hardware now works with GCC 11.x as well.
Graphics 🖼️
Landed a change that improves the painting of tile fragments in the compositor if damage propagation is enabled and if the tiles sizes are bigger than 256x256. In those cases, less GPU is utilized when damage allows.
The GTK and WPE ports no longer useDisplayList to serialize the painting commands and replay them in worker threads, but SkPictureRecorder/SkPicture from Skia. Some parts of the WebCore painting system, especially font rendering, are not thread-safe yet, and our current cross-thread use of DisplayList makes it harder to improve the current architecture without breaking GTK and WPE ports. This motivated the search for an alternative implementation.
Community & Events 🤝
Sysprof is now able to filter samples by marks. This allows for statistically relevant data on what's running when a specific mark is ongoing, and as a consequence, allows for better data analysis. You can read more here.
Update on what happened in WebKit in the week from March 17 to March 24.
Cross-Port 🐱
Limited the amount data stored for certain elements of WebKitWebViewSessionState. This results in memory savings, and avoids oddly large objects which resulted in web view state being restored slowly.
Multimedia 🎥
GStreamer-based multimedia support for WebKit, including (but not limited to) playback, capture, WebAudio, WebCodecs, and WebRTC.
The built-in JavaScript/ECMAScript engine for WebKit, also known as JSC or SquirrelFish.
Fixed an integer overflow when using wasm/gc on 32-bits.
Graphics 🖼️
Landed a change that fixes a few scenarios where the damage was not generated on layer property changes.
Releases 📦️
WebKitGTK 2.48.0 and WPE WebKit 2.48.0 have been released. While they may not look as exciting as the 2.46 series, which introduced the use of Skia for painting, they nevertheless includes half a year of improvements. This development cycle focused on reworking internals, which brings modest performance improvements for all kinds of devices, but most importantly cleanups which will enable further improvements going forward.
For those who need longer to integrate newer releases, which we know can be a longer process for embedded device distrihytos, we have also published WPE WebKit 2.46.7 with a few stability and security fixes.
Accompanying these releases there is security advisory WSA-2025-0002 (GTK, WPE), which covers the solved security issues. Crucially, all three contain the fix for an issue known to be exploited in the wild, and therefore we strongly encourage updating.
Update on what happened in WebKit in the week from March 10 to March 17.
Cross-Port 🐱
Web Platform 🌐
Updated button activation behaviour and type property reflection with command and commandfor. Also aligned popovertarget behaviour with latest specification.
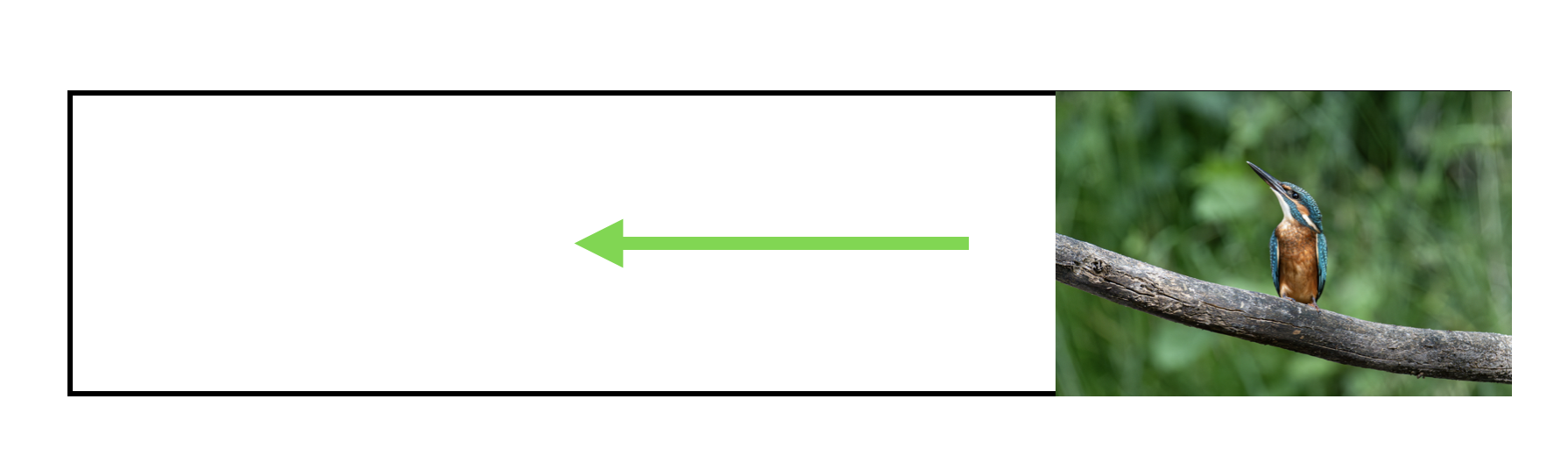
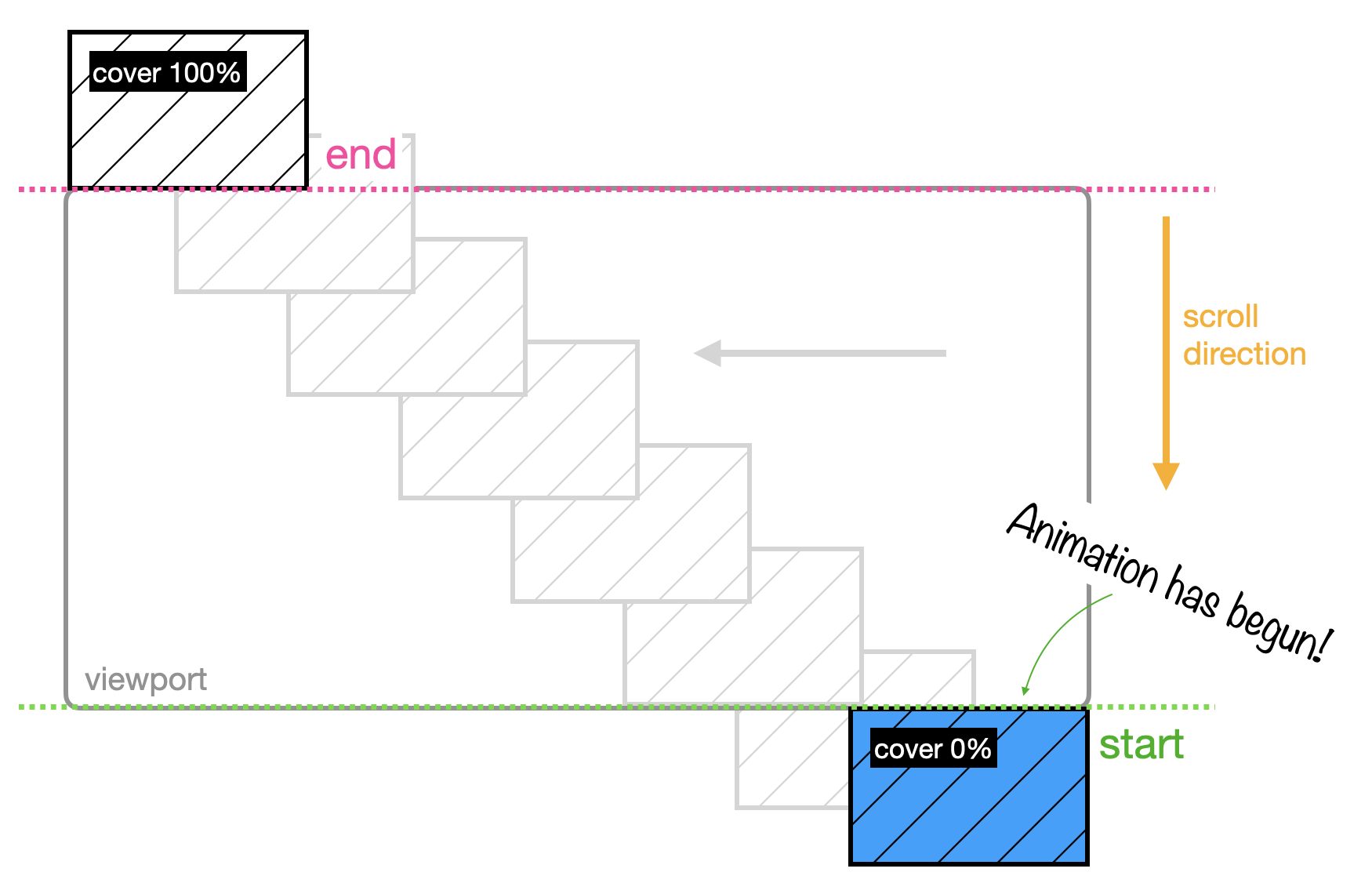
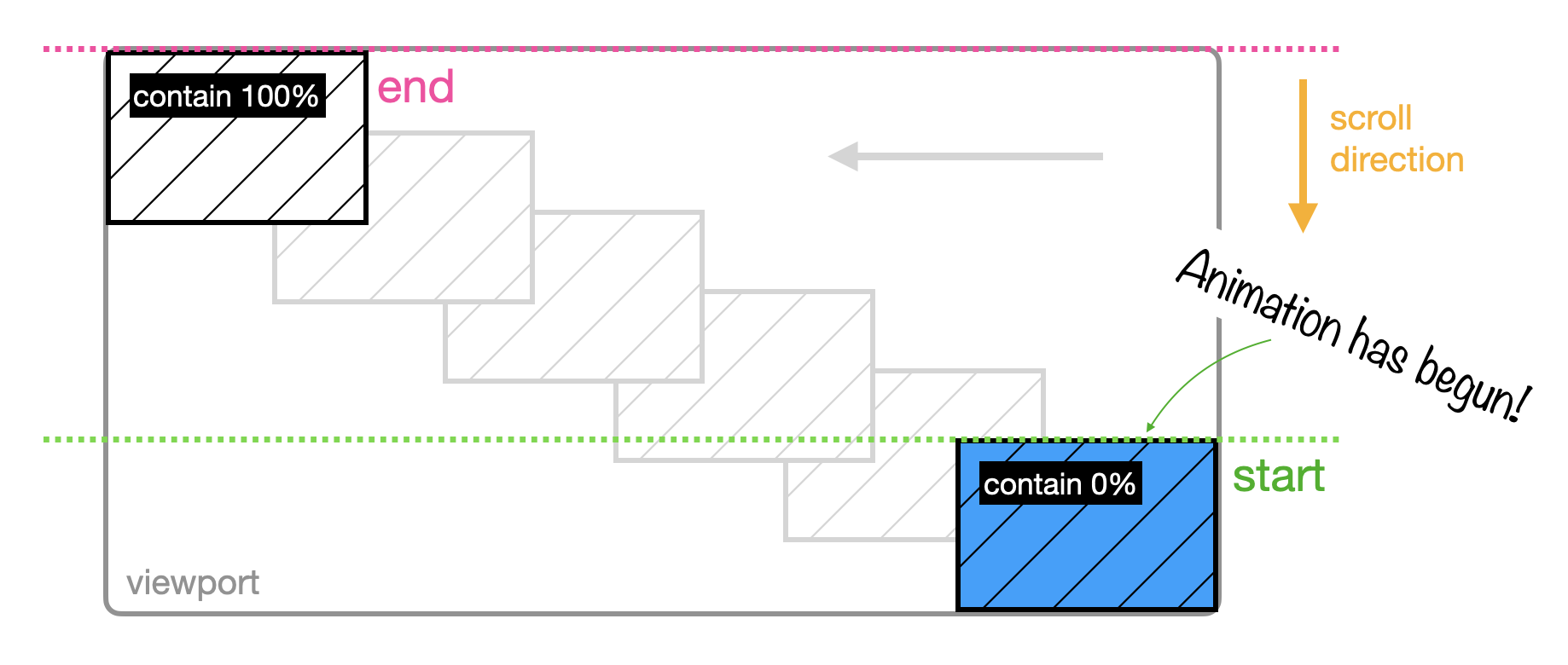
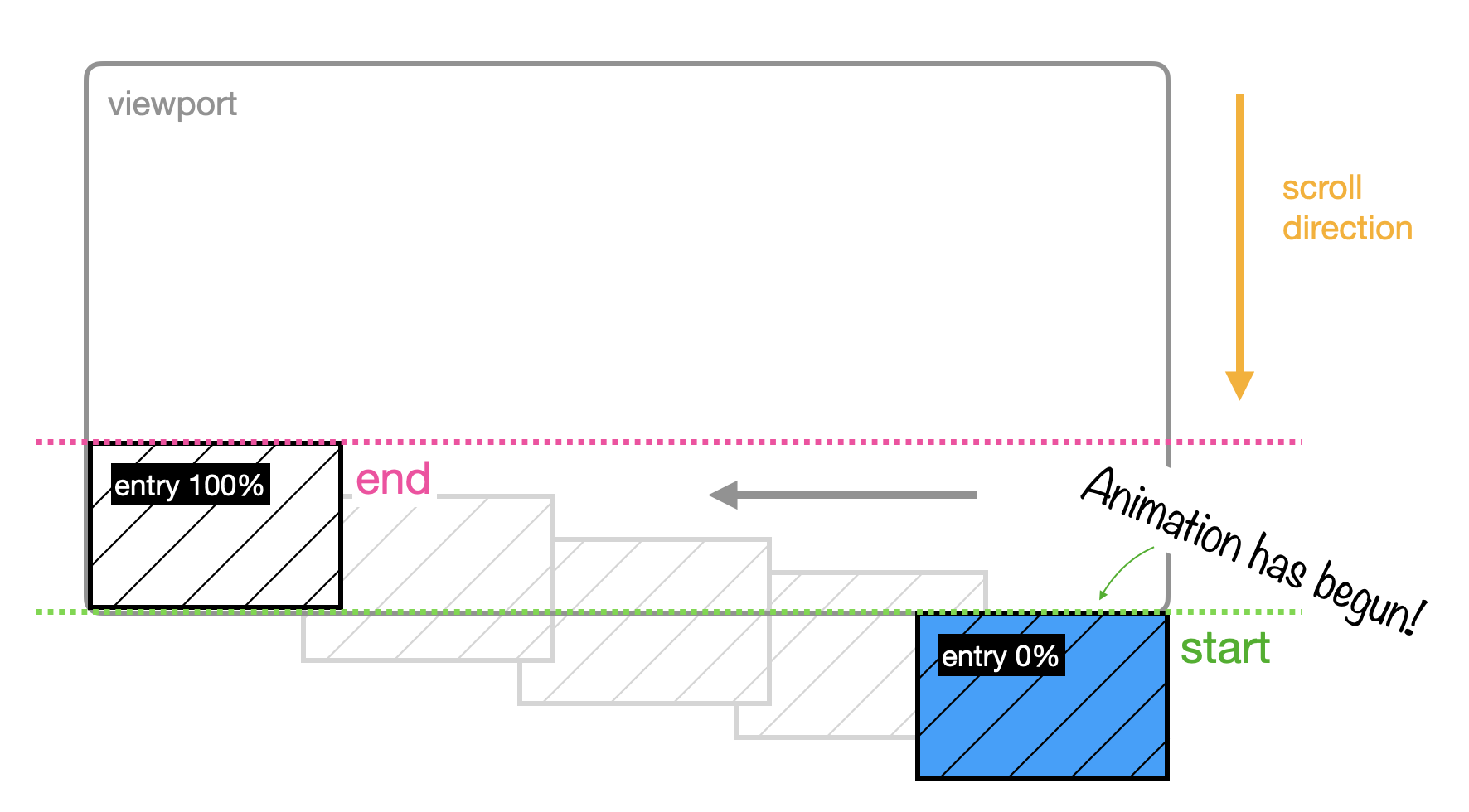
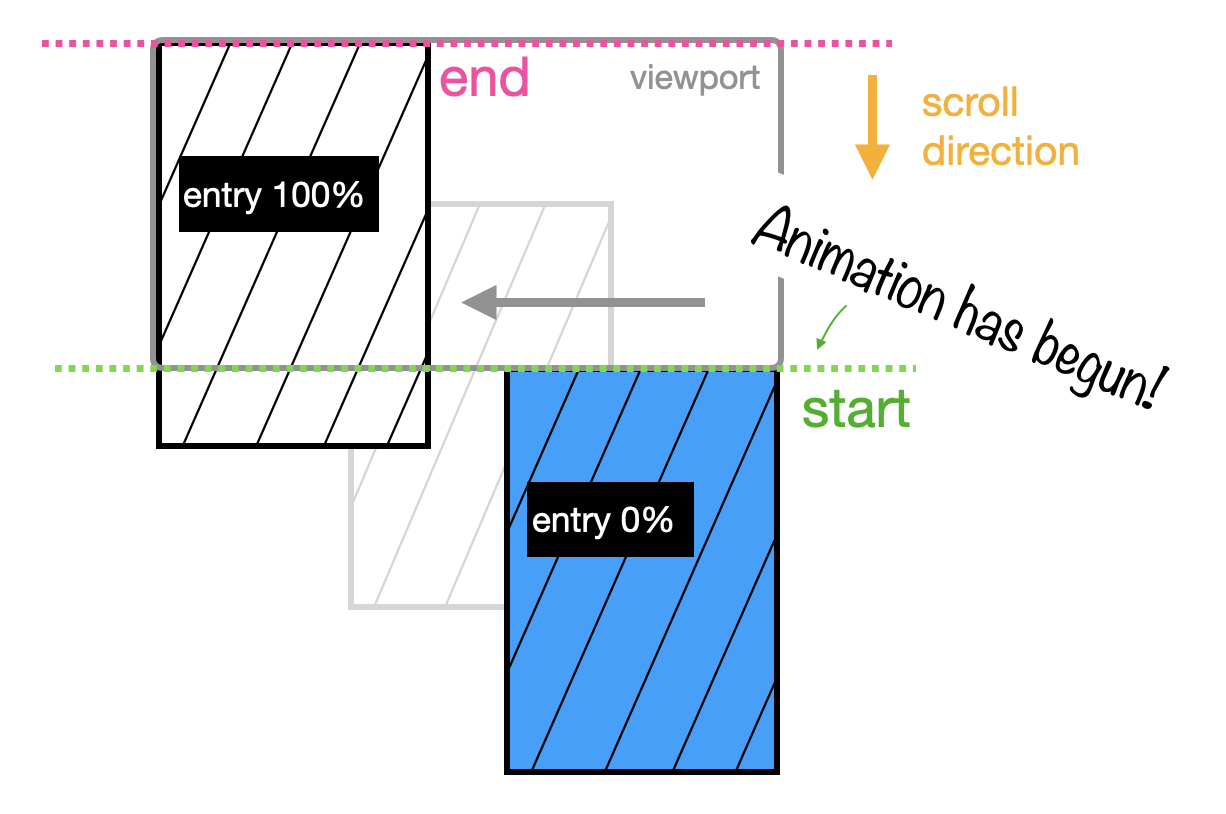
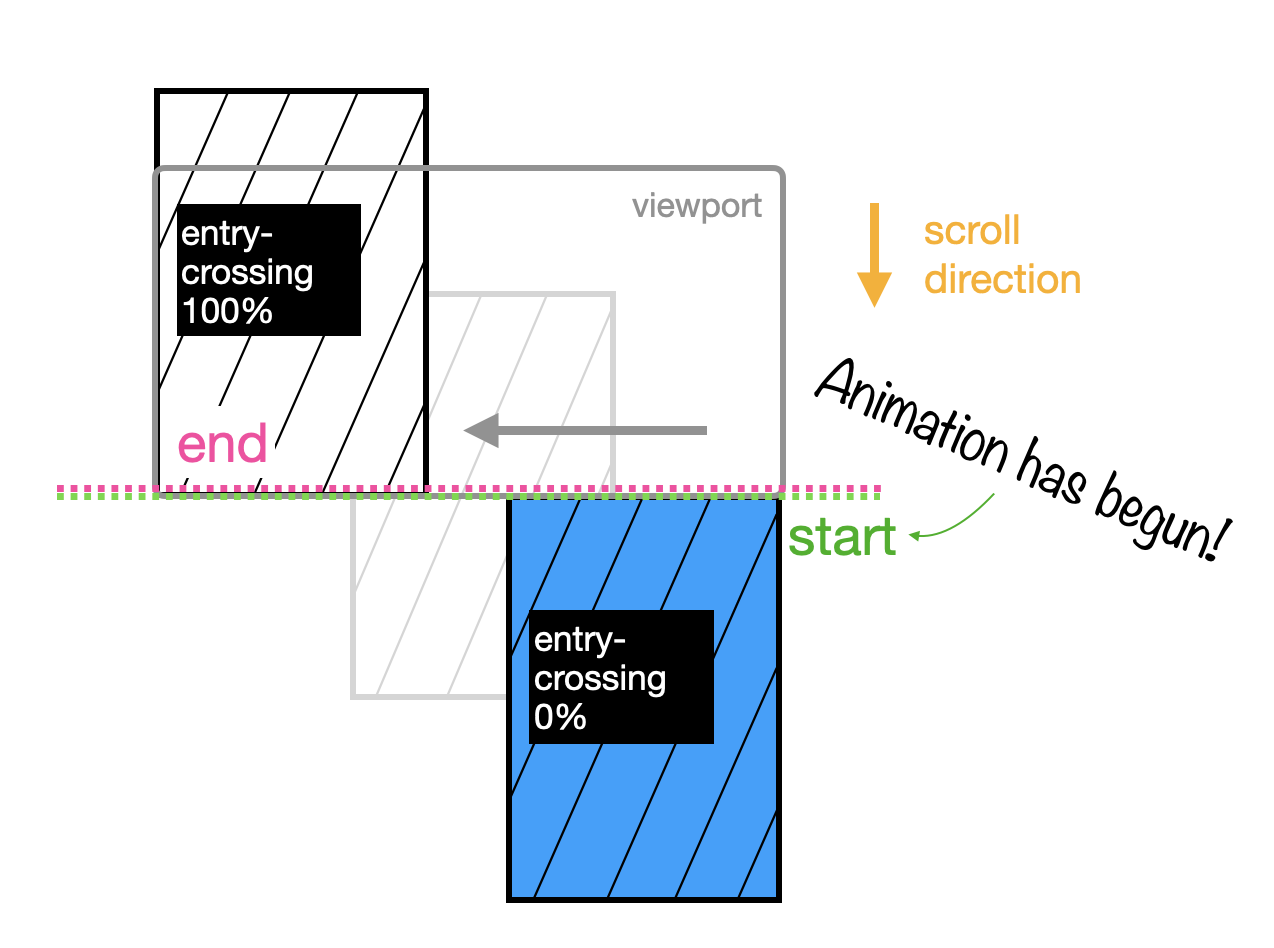
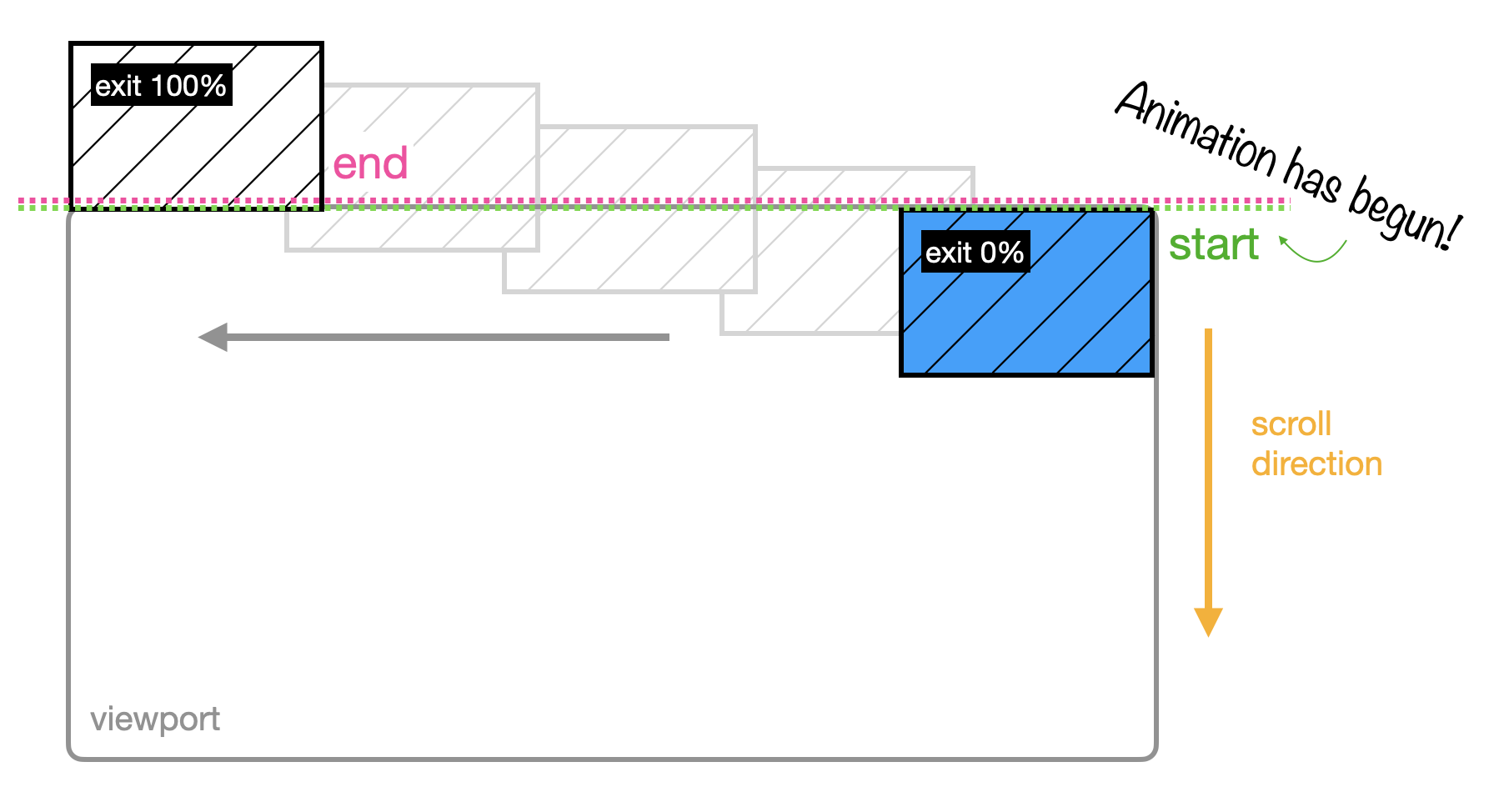
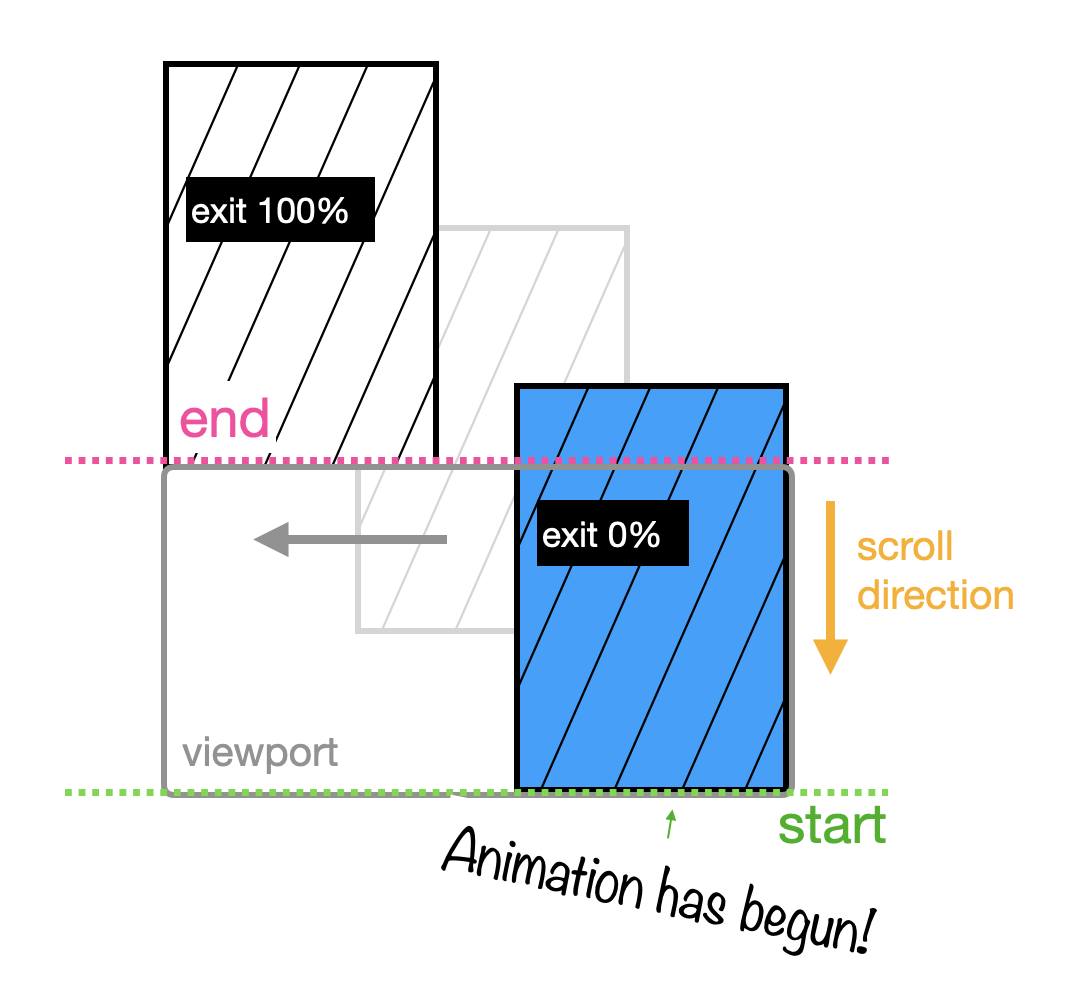
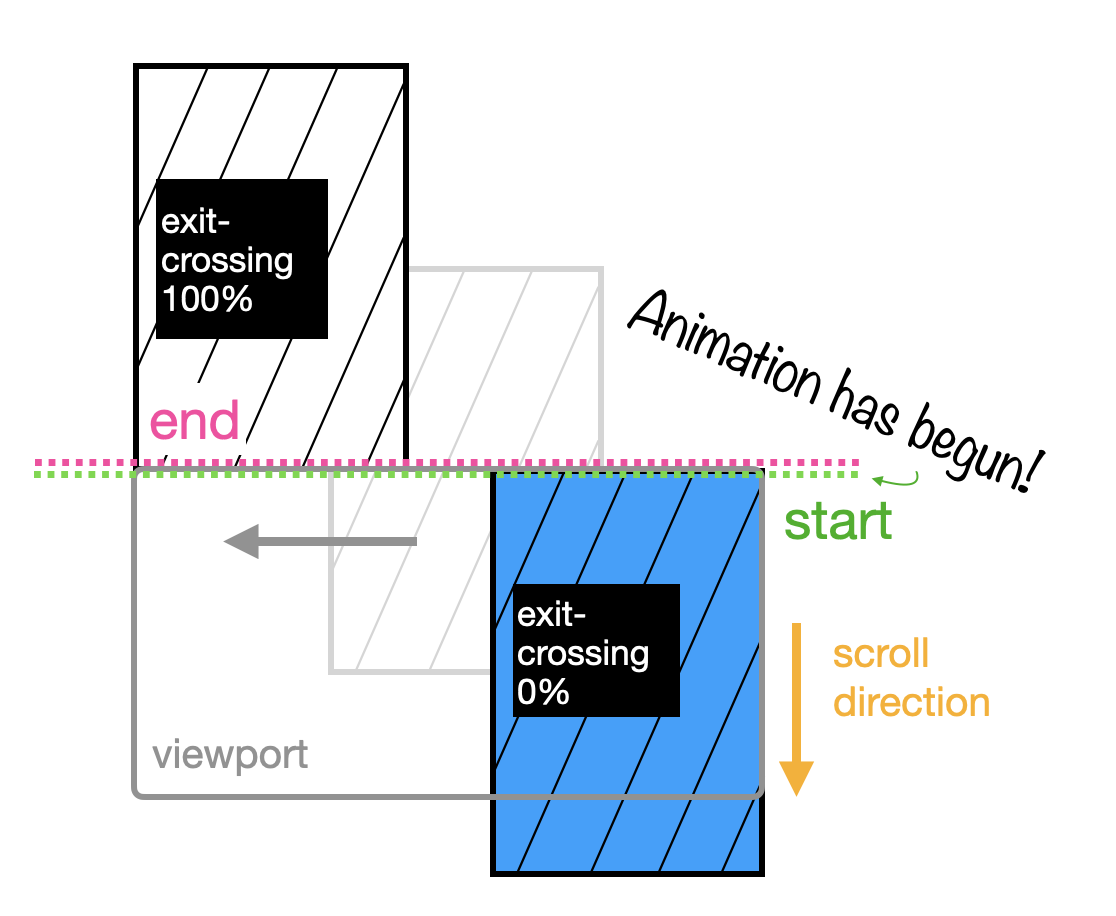
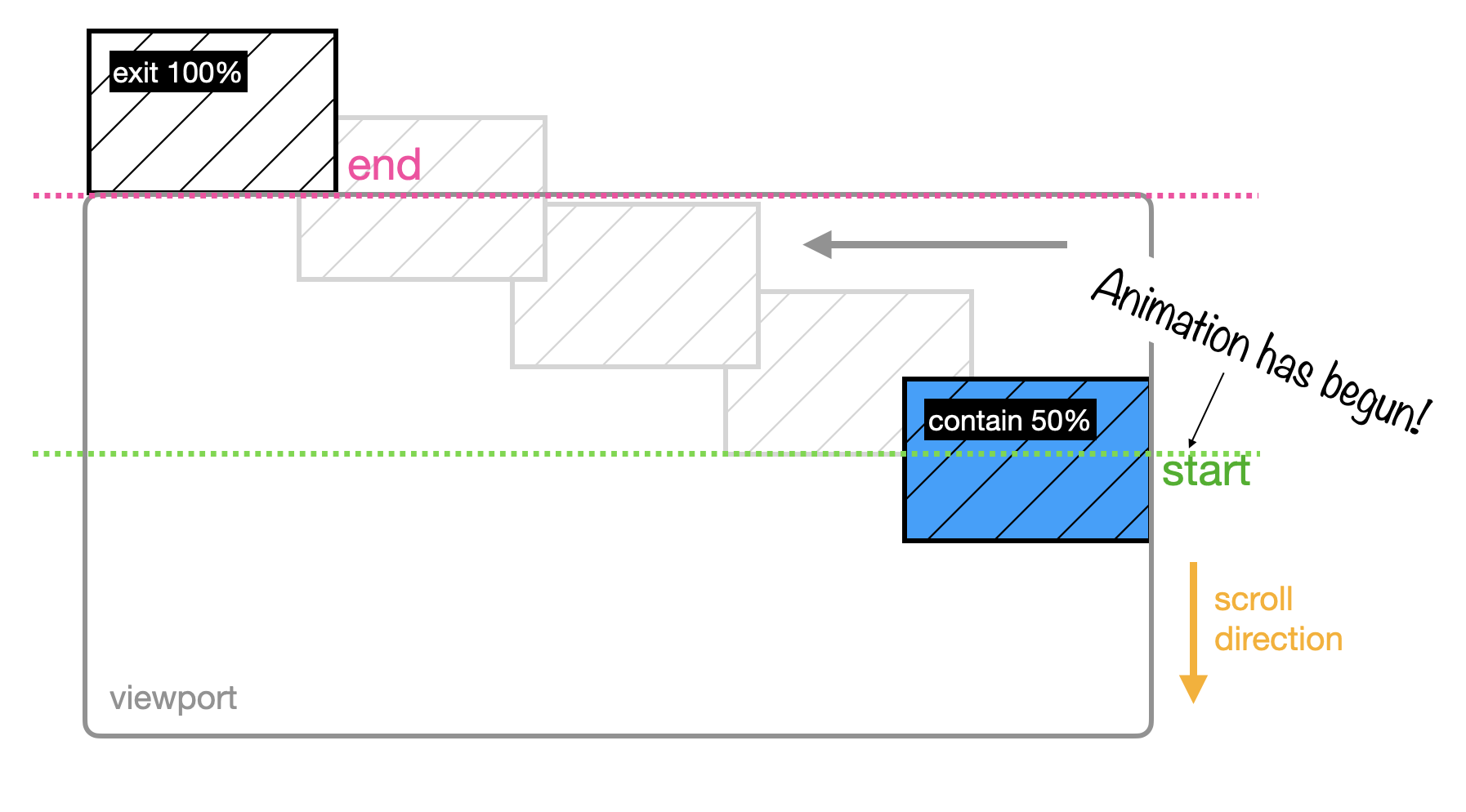

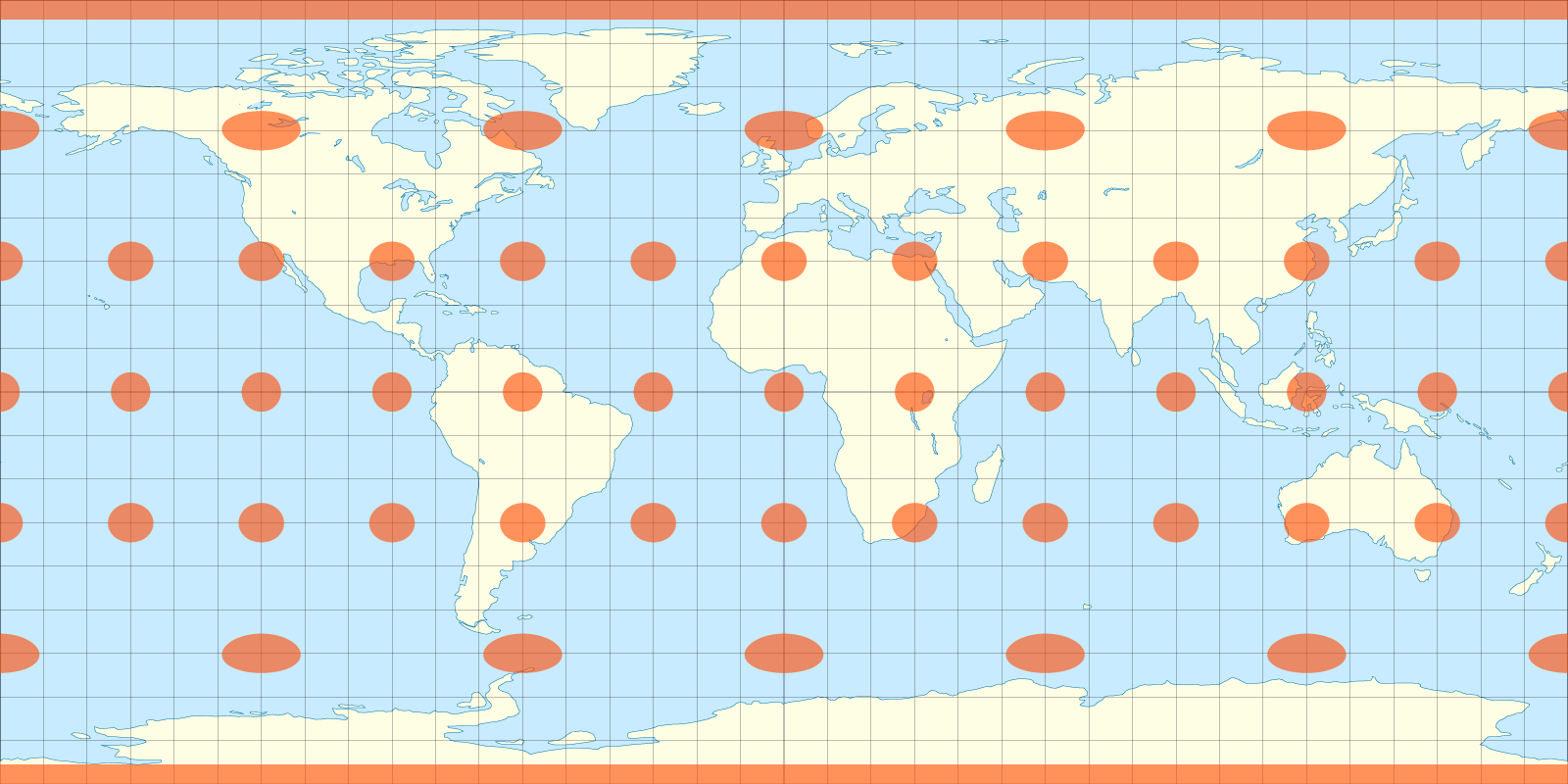


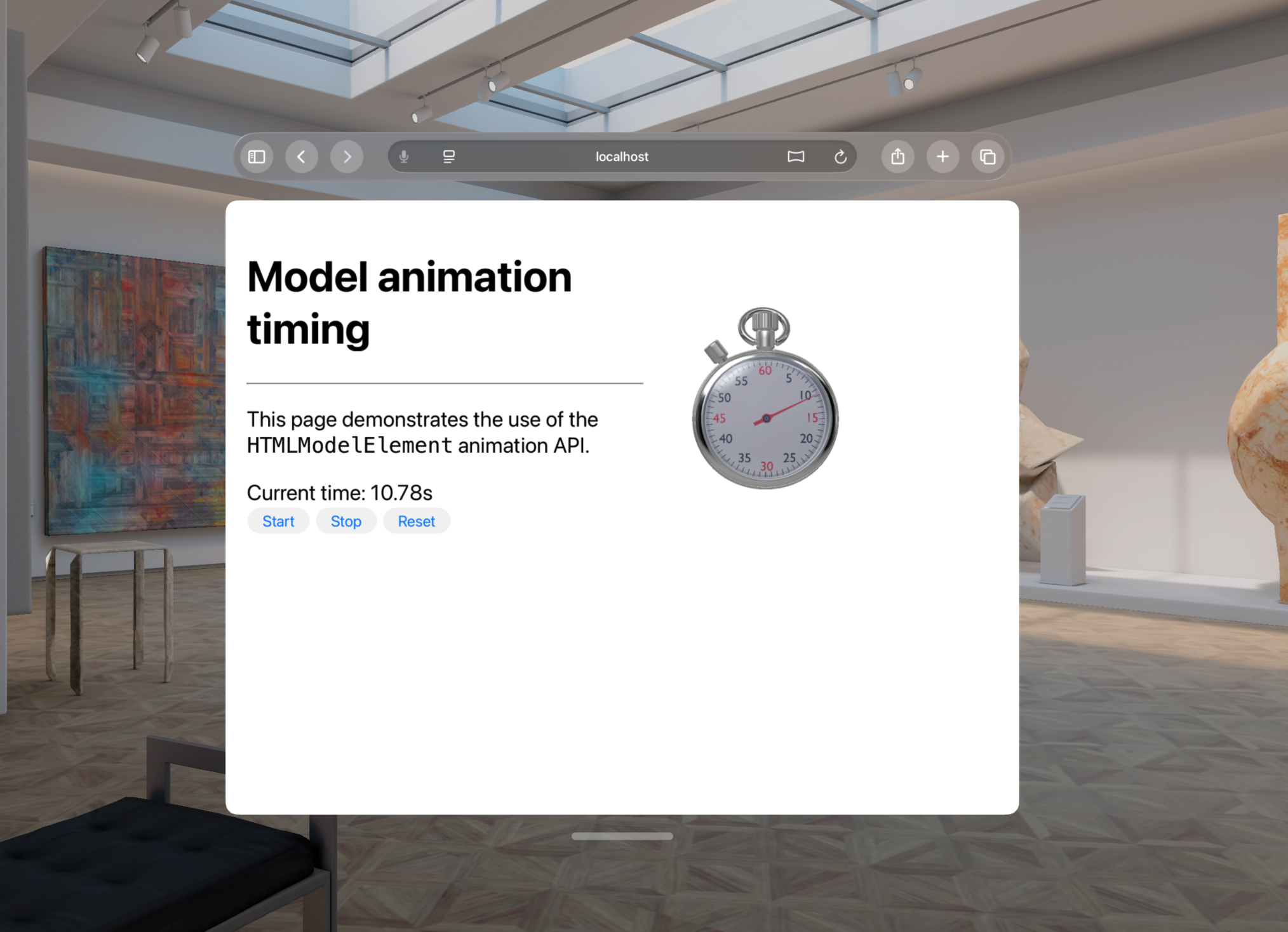




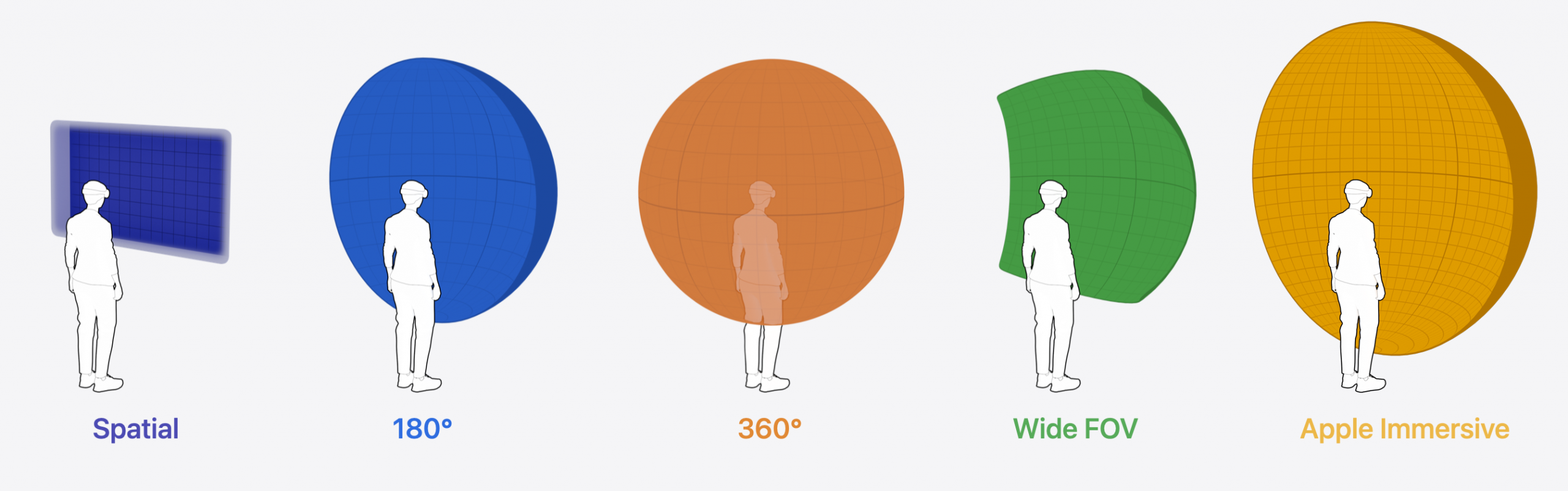



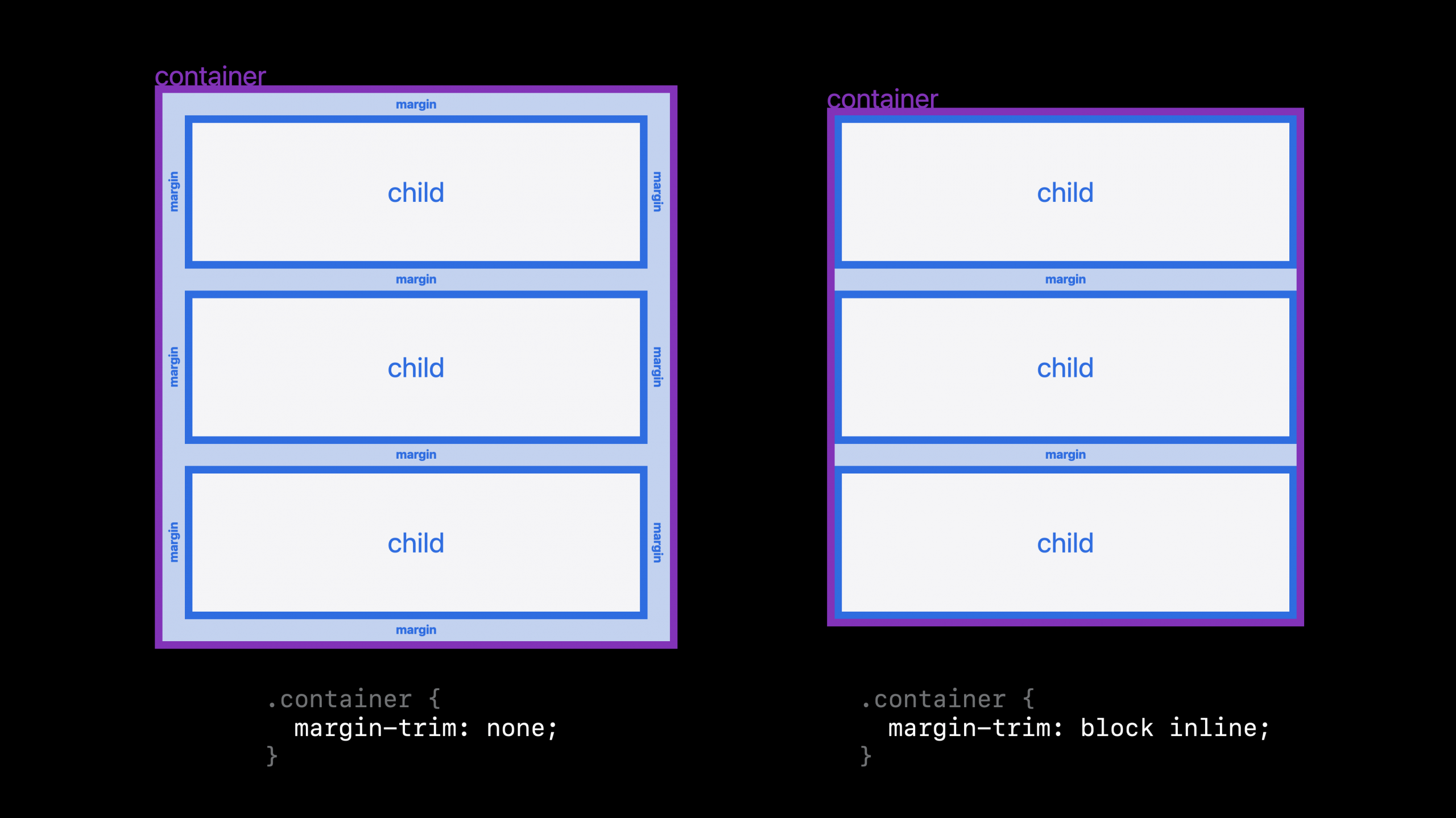
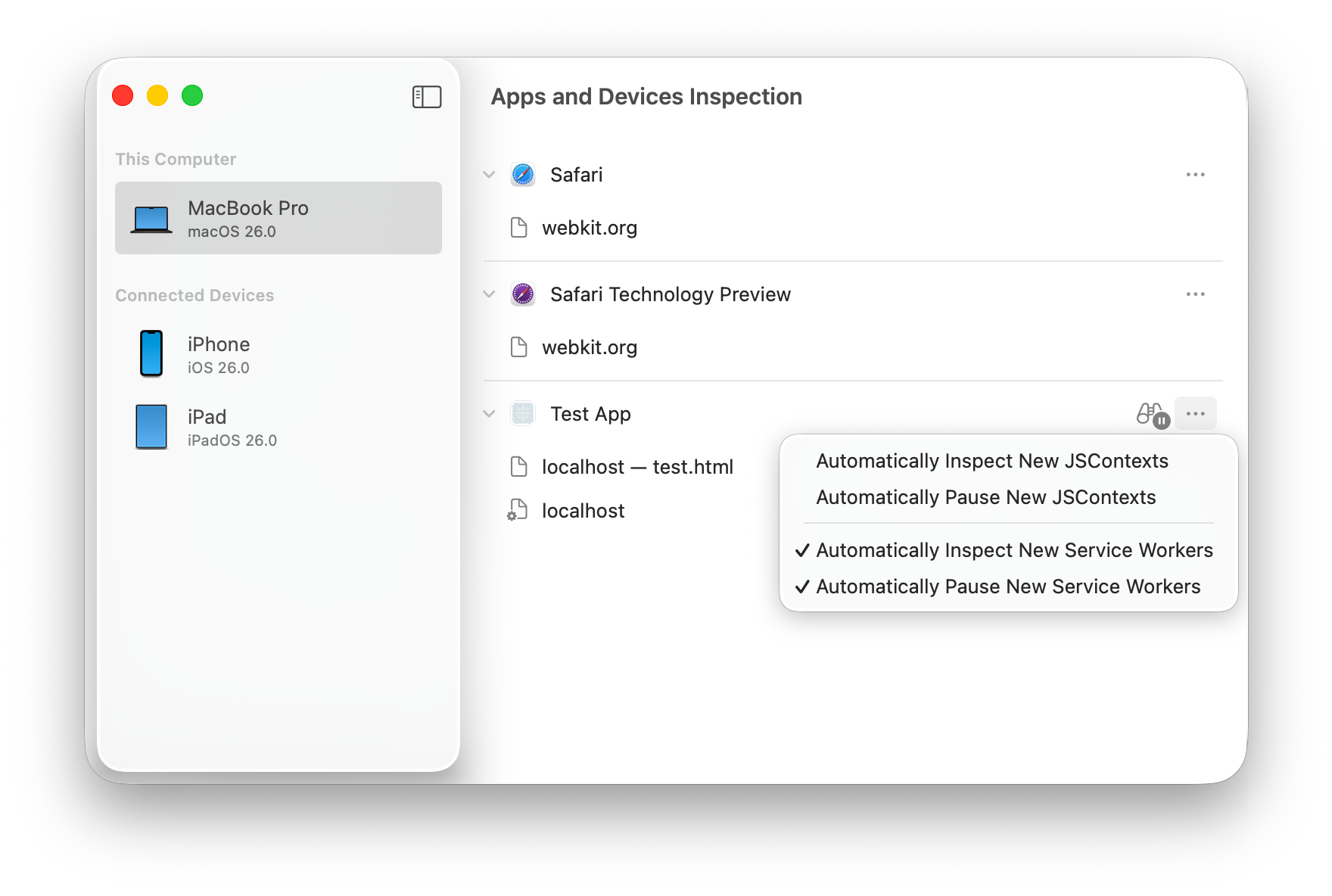











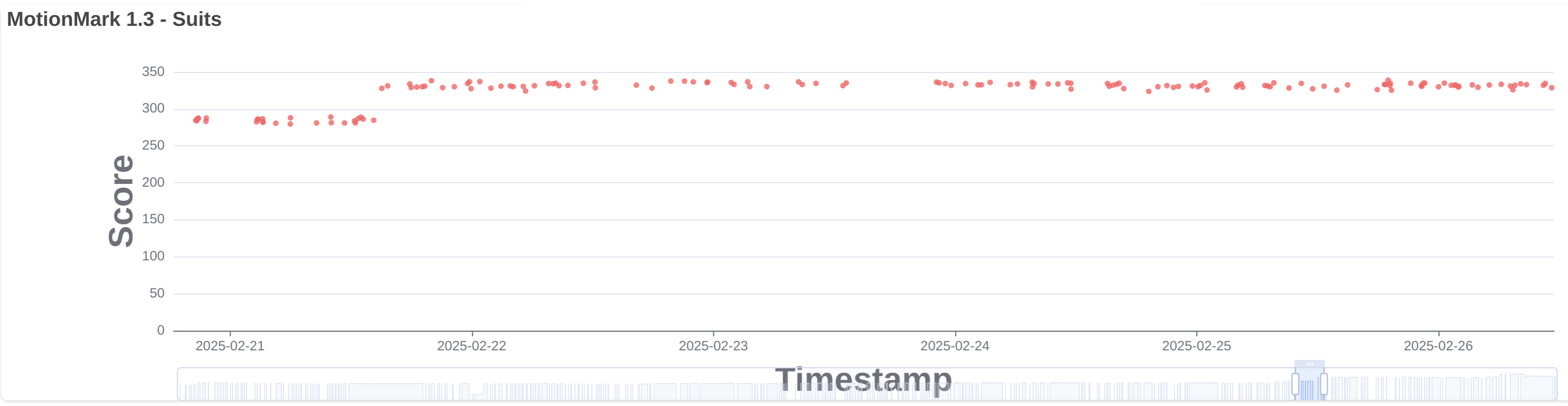
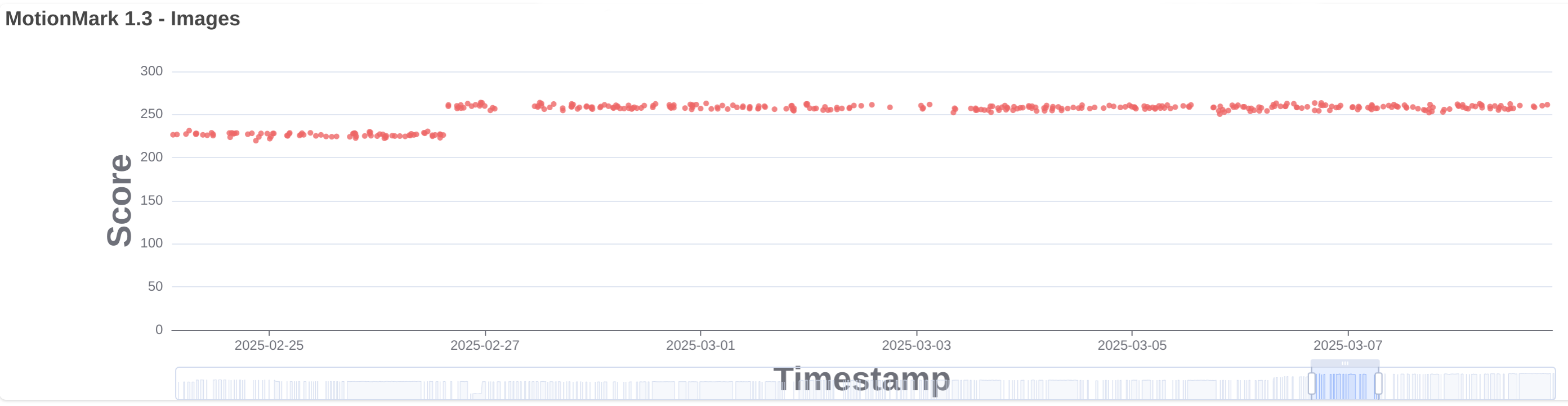
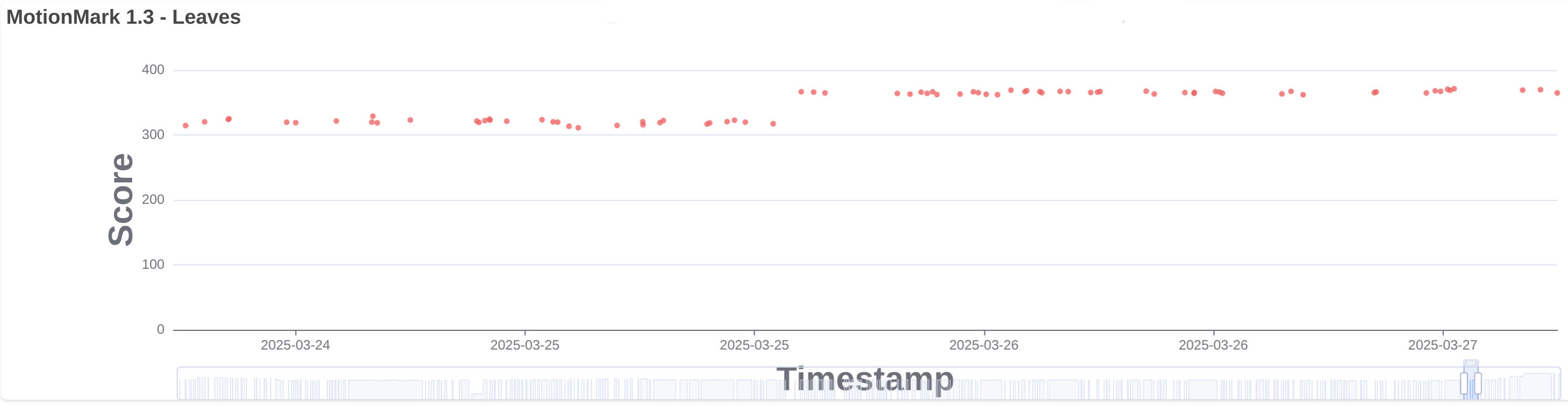
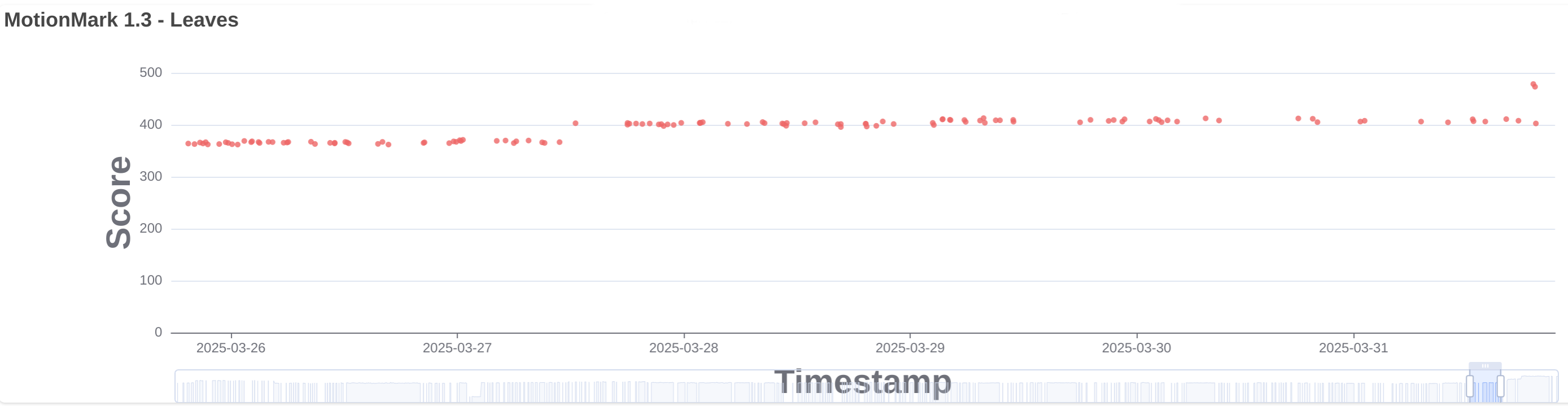
 In the image above, one can see the following elements:
In the image above, one can see the following elements: